![]()
HL-LHC computational challenge for ATLAS and CMS experiments
The two general purpose LHC Experiments, ATLAS [1] and CMS [2], are going to be confronted with challenging experimental conditions at the High Luminosity LHC Run (HL-LHC), starting in 2026. In particular, computing systems will have to cope with greatly increased data samples and data acquisition and processing rates.
While the collision centre-of-mass energy of 14 TeV is not going to change with respect to the previous run, the instantaneous luminosities, and thus the event complexity at each bunch crossing, are going to increase substantially. For every bunch crossing, about 200 low-energy collisions are expected to accompany the hard process selected by the experiments’ trigger systems. This has to be compared with the Run-2 average number of 35 collisions.
The increased event complexity by ~6x (from 35 to 200) is not the only source of additional computing load. ATLAS and CMS will install by 2026 new detectors with extended performance, with increased channel count and in general more complex to reconstruct. On top of that, the two experiments are planning to expand the trigger rate from the current 1 kHz, possibly up to 10 kHz, meaning that every second up to 10,000 events can be written on to disk.
The need for computing resources generally scales differently with the resource type. Storage (disks, tapes) scale roughly linearly with event complexity and trigger rate; by the above estimates, 2027 needs should be roughly x5 (event complexity) to x10 (trigger rates) larger than for 2018. Processing needs scale more than linearly, due to the combinatorial behavior of most time-consuming algorithms like tracking and clustering; in the same conditions, CPU needs will scale as much as 100x with respect to 2018 needs.

Of course we expect that technology advancements in the fields of processors and storage will help closing the gap. Recent estimates [3], though, tell us that in the period 2018-2027 a maximum improvement of a factor 5 or 6 is expected. Back-of-the-envelope estimates say that the annual cost of computing for ATLAS and CMS could increase by a factor between 10 and 20 at the HL-LHC. Such an increase in funding is not feasible, hence the experiments have launched extensive R&D programmes in order to find solutions for a viable HL-LHC computing.
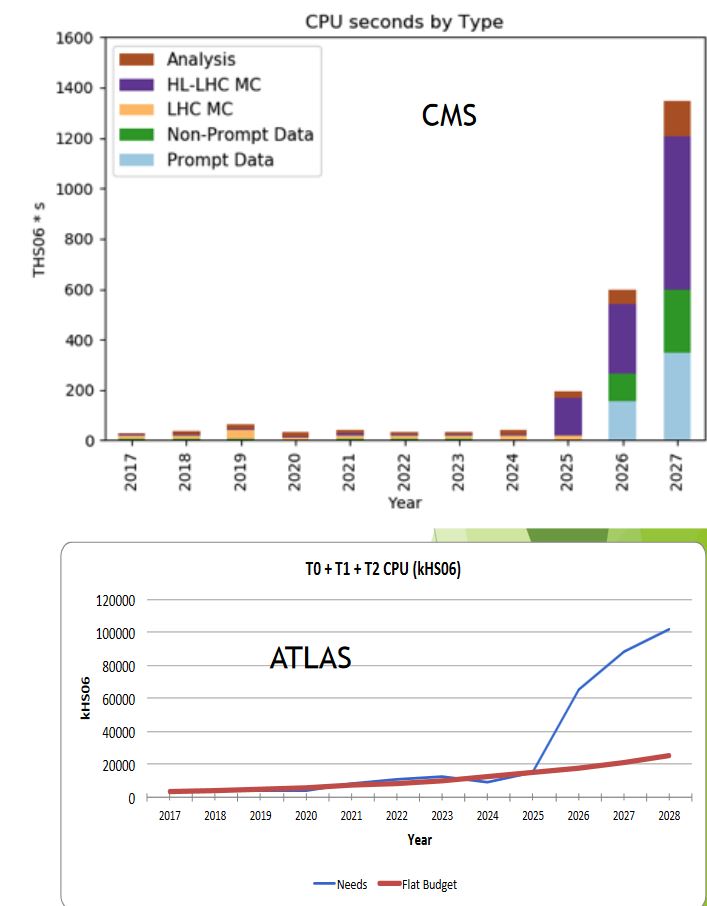
The differences between the two experiments estimates are mostly due different R&D paths but a common underlying message is that further R&D is needed to meet the challenges of HL-LHC.
Current directions include the utilization of GPUs, FPGAs and other state of the art computing technologies in order to lower the cost of processing, and optimized models and infrastructures for a cheaper storage solution.
The mainstream path towards a viable HL-LHC computing for ATLAS and CMS does not currently include options that could benefit from Quantum Computing / Quantum Technologies. Though the technology is promising in the long run, it seems too early to base our model on its availability at large scale.
There are at least two aspects in Quantum Technologies that can be relevant to HEP Experiments, in the medium-long time range: the utilization of Quantum Simulators and the so-called Quantum Supremacy for computing.
Simulators are quantum systems which, at least locally, reproduce the behavior of other quantum systems, in a controlled environment. Already now simple systems have been demonstrated[4], and it is not unrealistic to think that with theory and technological evolution, systems of interest for HEP like QED, QCD, or the full Standard Model can be deployed on a quantum system setup.
Quantum supremacy is the ability of quantum computers to surpass in performance any classical system; it is due to the exponential scaling of quantum systems with the number of qubits N, which at large N cannot be matched by any non-quantum system. It is largely theoretical at the moment, given the systems commercially available.
Following a workshop held at CERN on November 5th and 6th[5] it became clear that the technological and evolution the Quantum Computing is in an exponential phase. Today machines with tens of qubits are commercially available via Cloud interfaces. At the same time, user friendly programming toolkits have been made available to test Quantum Algorithms on real machines or software emulators; at least four of them were presented at the workshop. They are generally based on Python, and already integrated with the main Data Analysis frameworks used in High Energy Physics, like Numpy, TensorFlow and Scikit-learn. A typical class of problems considered ideal for Quantum computing is when in presence of combinatorial algorithms, like the reconstruction and identification of tracks and clusters; an example at the former has been given at the workshop.
Given the involvement of major players in the IT technology, like Google, IBM, D-wave, Intel, Microsoft and many more, it is not possible to exclude a major technological breakthrough on a shorter than expected time scale. The experiments are suggested to perform R&D activities on quantum technologies, in order to gain understanding and experience on such novel systems. This has already started in some cases, as the presentations at the workshop show, but the level of commitment needs to be increased and coordinated within the experiment managements.
In this phase, it is essential that researchers are guided and helped by experts in the field, and are able to access quantum machines and emulators via preferential paths. We therefore welcome the initiative CERN/OpenLab has started, and hope we will be able to contribute to a closer interaction between High Energy Physics and Quantum Computing research fields.
Further reading:
[3] https://twiki.cern.ch/twiki/bin/view/Main/TechMarketPerf
[4] https://journals.aps.org/prx/abstract/10.1103/PhysRevX.6.011023
[5] https://indico.cern.ch/event/719844/timetable/