![]()
First SWAN workshop at CERN
![]() The first SWAN (Service for Wab based ANalysis) and Jupyter Notebooks Users’ Workshop was held last October at CERN. One of the main goals of the meeting was to offer a space where users could openly share their experience and gather feedback for develpments that could improve the service to serve future needs.
The first SWAN (Service for Wab based ANalysis) and Jupyter Notebooks Users’ Workshop was held last October at CERN. One of the main goals of the meeting was to offer a space where users could openly share their experience and gather feedback for develpments that could improve the service to serve future needs.
The workshop was divided in two sessions, one in the morning and another one in the afternoon. The morning session started with a few presentations from the SWAN team, which gave an overview of the service and introduced the new features that are foreseen for the service, for example the migration of the interface to JupyterLab, the possibility to offload computations to GPUs from SWAN; moreover, the ScienceBox software package was presented as a way to easily deploy private SWAN instances on premises. After that, a block of presentations from the experiments followed, which explained how they use SWAN to do their analyses, mainly from Python. They highlighted SWAN features such as the integration with CERNBox and EOS for persistent storage and the ready-to-use software provided by CVMFS.
Furthermore, they brought up two main topics: first, the fact that SWAN users could benefit from collaborative notebooks, that is, being able to share notebooks with your colleagues that everyone can edit, even concurrently; second, the possible need to increase the memory provided by a SWAN session, in order to support use cases that load big datasets into memory. On the other hand, some presenters showed their efforts in configuring experiment software, in particular for ALICE and CMS, on top of the LCG releases, and it was discussed how to make such process work more smoothly. Finally, the morning session also included a presentation that showed the experience of an Australian company, AARNet, that is running its own instance of SWAN for more than 3700 users.
In the afternoon session, the Beams and the Technology departments explained how they are using SWAN to query and analyse LHC log data, either by connecting to a database directly from a notebook or, as done in the NXCALS project, by offloading computations to Spark clusters from SWAN. Moreover, the TE colleagues also explained how SWAN is used to generate superconducting magnet files and how it helps in the LHC Signal Monitoring Project, with features such as rapid prototyping, easy sharing of notebooks, plug-and-play style of working and better reproducibility; they also stated that GPUs could be an asset for them and would speedup some of their workflows. The IT department and the HSE unit were also represented with talks about using SWAN to analyse tape server logs and in the area of operational radiation protection, respectively. Finally, a block of presentations on SWAN for education and outreach highlighted the value of SWAN for hosting tutorials and courses and for accessing open data, and they advocated for having an open instance of SWAN for education, which would need to be accessible with lightweight accounts..

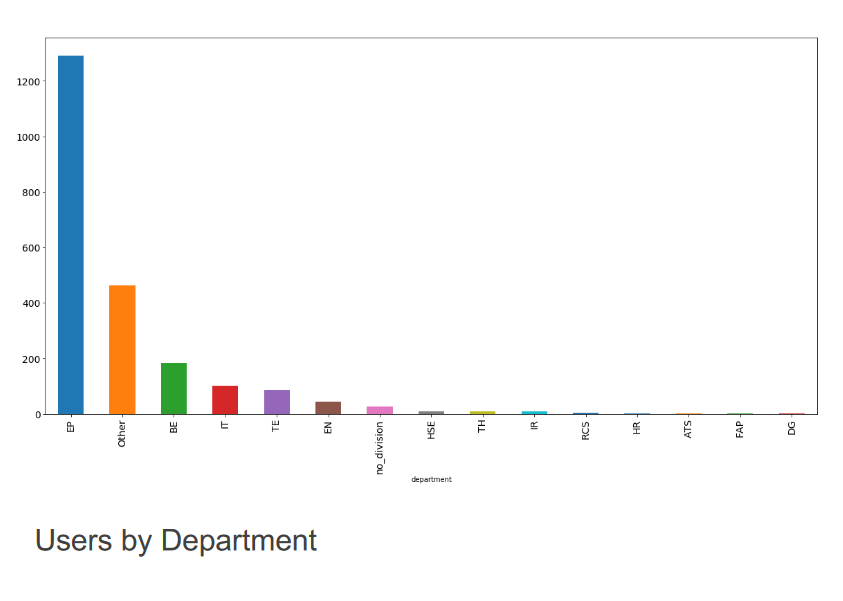
Plots showing the number of SWAN users per experiment (top) and per CERN's Department (bottom). The two plots were presented during the workshop by Diogo Castro (see HERE).
In summary, the SWAN Users' Workshop was a great opportunity to bring together the SWAN user community and the SWAN team, get to know each other, exchange impressions about the service and discuss how it should evolve. Learning about how SWAN is used and what needs to be improved was crucial for the SWAN team to provide a better service to the users. This was only the first edition of the workshop, but more will come to keep in touch with the community.