![]()
A new CERN service for web-based data analysis in the cloud: SWAN
In the last few years, a clear trend has emerged in the data science industry: the increase of service offerings for data analysis in the cloud, accessible via a web interface. It is precisely this phenomenon that led us, the SFT and IT-ST groups, to the creation of SWAN, the CERN Service for Web-based ANalysis.

The SWAN Logo
SWAN offers an integrated environment for data analysis in the CERN cloud where the user can find all the experiment and user data together with rich stacks of scientific software. The interface offered by the service is the one of Jupyter notebooks. Notebooks have been chosen since they give access to a rich narrative made of code, text and formulas as well as multimedia material, all combined in an HTML page that can be rendered in a browser.
SWAN is not tied in particular to any programming language. Presently it offers the possibility to write notebooks in three languages: C++ (processed by Cling, the interpreter of ROOT), Python and R. An innovative element is represented by the fact that, thanks to ROOT, these languages can be seamlessly mixed: multilanguage notebooks can be created.
As a result of its integration with the Jupyter technoIogy, only a web browser is needed to use SWAN: data analysis can be performed without requiring any local software installation. Every computation happens on the server side - in the cloud - while the results are displayed on the client's browser. Regarding the data, both input and output files also reside in the cloud, with EOS acting as a cloud storage backend: the work directory is the user space located on EOS. The exciting part about this solution is that the files in the cloud can be synchronised on local devices and vice-versa thanks to CERNBox. In addition, the sharing functionality of CERNBox allow to quickly involve colleagues in the development of notebooks.
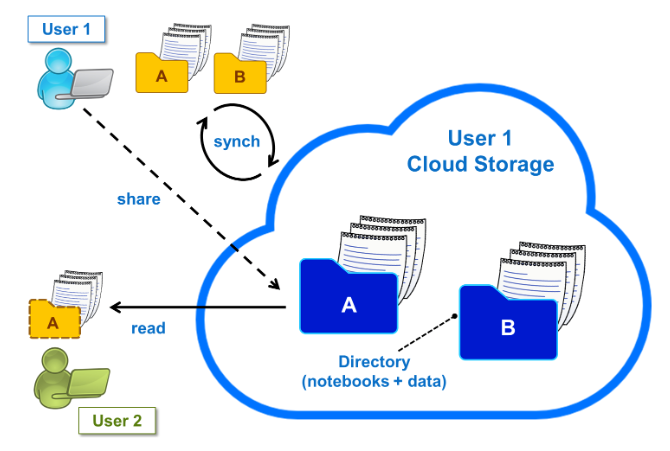
User 1 is synchronising with CERNBox two directories in the cloud. They contain notebooks and other data les. Directory A can be shared with User 2.
Setting up a software environment that satisfies the needs of an advanced analysis usually requires quite some work: several packages have to be compiled and installed, the right versions need to be picked up. With SWAN there is no such difficulty: software stacks of more than 200 packages can be directly accessed by the notebooks in a transparent way thanks to the CVMFS distributed file-system. These stacks are the LCG releases, adopted by LHC experiments and provided by the SFT group. Products like Fastjet, Pandas, Matplotlib, Numpy, a full palette of Monte Carlo generators, Geant4 and ROOT are part of the LCG releases. In particular ROOT evolved in the recent months to integrate with Jupyter notebooks. In this novel environment, all the power and functionalities provided by the ROOT framework are now available. In some sense, SWAN can be considered a veritable ROOT-as-a-Service system!
The LHC Page 1 created in a notebook. SWAN provides a way to connect to the Timber database, fetch the information, plot it and document it from within the web browser. See https://swan.web.cern.ch/content/accelerator-complex for more examples.
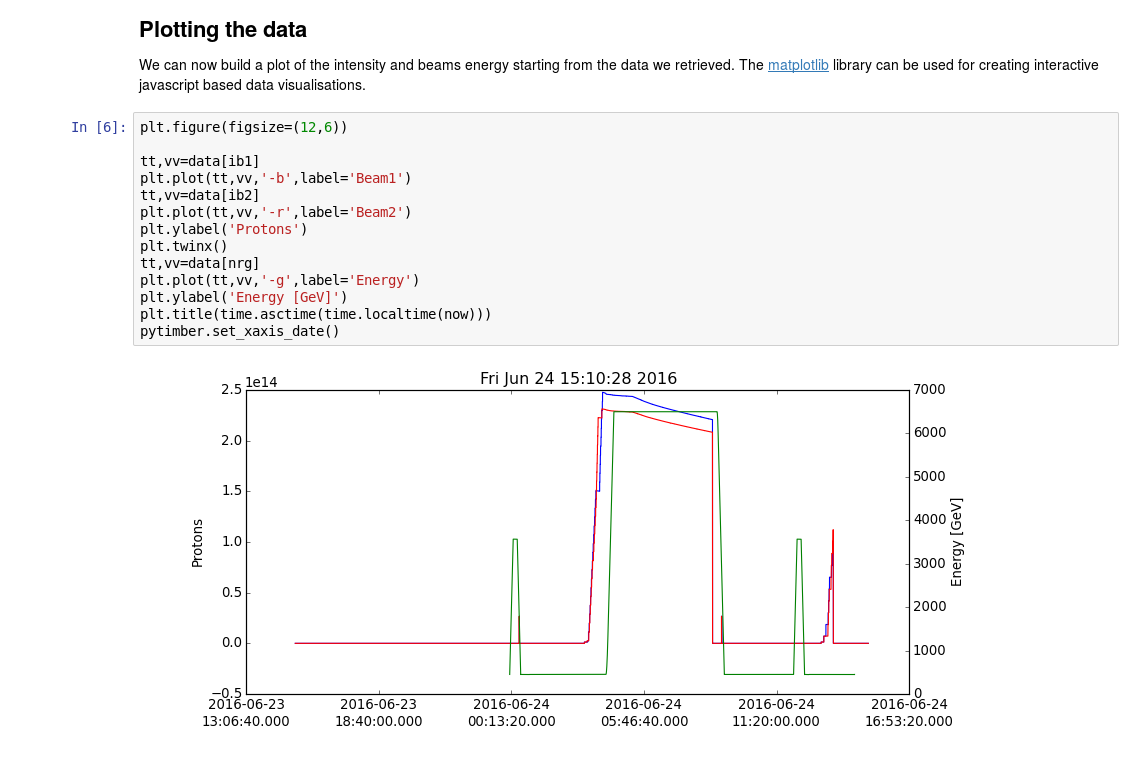
The LHC Page 1 created in a notebook. SWAN provides a way to connect to the Timber database, fetch the information, plot it and document it from within the web browser. See https://swan.web.cern.ch/content/accelerator-complex for more examples
SWAN is a prototype service but it is managed as if it were part of the CERN production infrastructure: several tens of users from different departments such as BE, EN, IT and EP have made it already part of their daily workflows! SWAN is not only useful for everyday data analysis and visualisation but also ideal for the organisation of tutorials and teaching events: it served this purpose in several occasions already such as the ROOT Tutorial for Summer Students, the Apache Spark tutorial by IT-DB-SAS or the CERN School of Computing.
We believe SWAN also represents yet another a step towards reproducible science. The notebook format is ideal to mingle theoretical considerations, detailed explanations, code and scientific results in form of data visualisations. Furthermore, the fact of being in condition to select a well defined software ecosystem (a particular LCG release) identical for every user is a requirement to achieve reproducibility of results.
The program of work ahead of SWAN is very ambitious. First of all we will continue to integrate all the precious feedback that the user community is providing. In addition, we will bring to production the interface of SWAN with the Hadoop and Spark clusters of CERN, in order to provide the service with external computational power. Finally, we will continue to integrate the experiments’ software setups within the SWAN ecosystem.
SWAN reference paper: SWAN: a Service for Interactive Analysis in the Cloud Paper submitted to Future Generation Computer Systems — The International Journal of eScience