![]()
Scientific data management with Rucio

Today's scientific experiments are manifold and diverse in their objectives, size, and workflows. However, one commonality uniting most, if not all, scientific experiments is the creation and analysis of data. Managing these scientific datasets is becoming an increasingly complex and complicated challenge. We have evolved from storing data in single devices, to using storage infrastructures filling entire data-centers, up to today where we are storing the data in numerous geographically dispersed data warehouses, interconnected by massive high-bandwidth networks. But this path is just at the beginning. With the ever-increasing data volume needs of future experiments, such as the high-luminosity upgrade of the LHC, neutrino experiments such as DUNE, or upcoming astro-physics instruments like LSST or SKA, the need for efficient and cost-effective scientific data management has never been greater.
One prominent solution to tackle these challenges is the scientific data management system Rucio. Named after the reliable donkey of the famous Don Quixote novel, Rucio is an open-source software framework that provides scientific collaborations with the functionality to organize, manage, monitor, and access their distributed data at scale. It was designed based on more than ten years of experience with the distributed data management system DQ2 of the ATLAS experiment. While at the beginning the software was principally designed and developed by and for the ATLAS collaboration, it was understood very early that there is a clear need for data management in the big science landscape at large, as well as the potential of a community-driven data management solution. Consequently, Rucio was changed to the Apache open-source license and became a community-driven software project. Rucio was originally put into production for ATLAS in December 2014, following several years of development, integration, and migration effort. Soon after, the Xenon1T and AMS experiments expressed their interest in Rucio and after a thorough evaluation, it was put into production as the principal data management system for both experiments.
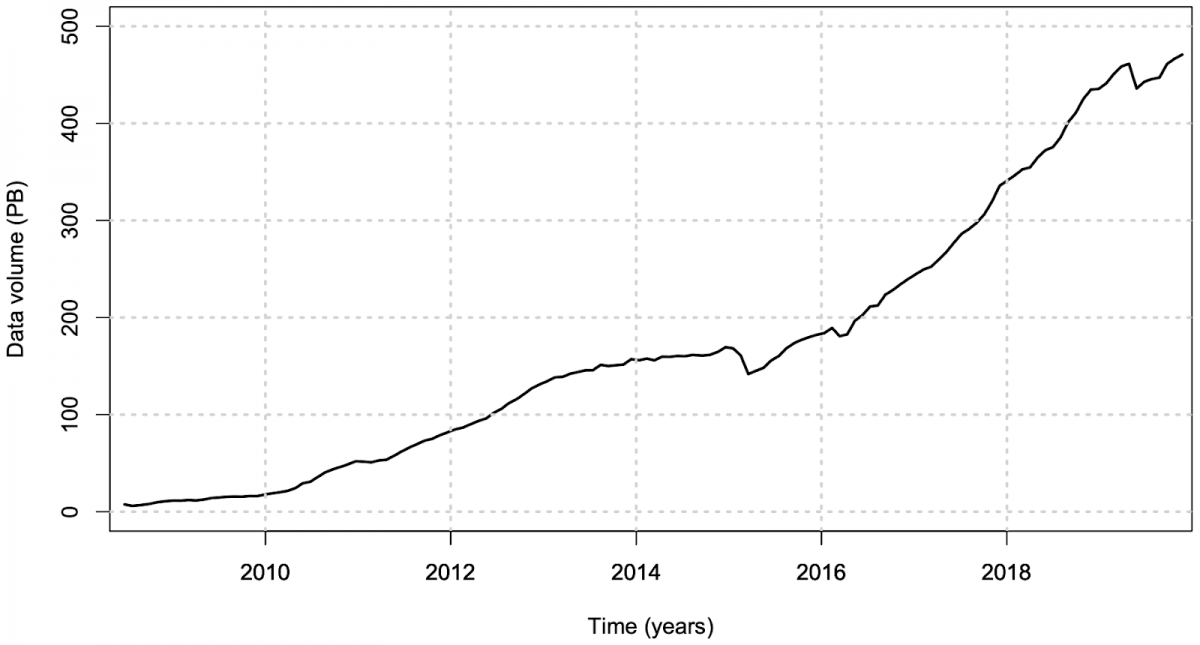
Figure 1. Worldwide ATLAS data volume managed by Rucio as of December 2019
The core motivation of Rucio is to shield the user from the complexity of the distributed infrastructure environments and to facilitate data access in a convenient and efficient way. Since the actual infrastructure is usually heterogeneous and involving technologies from different manufacturers and even commercial cloud providers, Rucio allows to present the data to the user in a federated way, effectively hiding these complications. This gives experiments and organizations the needed flexibility in choosing the technologies best fitting their use cases, given financial constraints. One of the pillars of Rucio is its ability to express data placement and lifetime requirements in a convenient rule-based language. This enables organizations to express their computing models and dataflows with policies that are continuously monitored and automatically enforced on the data. The system design follows the FAIR data principles, thus all data is Findable via a rich set of metadata, Accessible using standardized protocols, Interoperable using qualified references, and Re-Usable. The entire software stack is designed in a horizontally scalable way, allowing organizations to easily scale their deployment over time with increasing data requirements. Major system components, such as storage interaction protocols, interfaces to transfer systems or authentication mechanisms are designed in a pluggable way, allowing communities to expand the software to their needs. Furthermore, Rucio is compatible with numerous database systems to avoid vendor lock-in.
The first Rucio Community Workshop was hosted at CERN in 2018. This two-day workshop marked the kick-off of Rucio as a wider community project and brought together experts from ten scientific experiments to discuss data management needs and the evolution of the Rucio software stack. Since then a second workshop was hosted in 2019 by the University of Oslo and a third workshop is currently being prepared for 2020 at Fermilab near Chicago. The Rucio community has grown to over 30 organizations using, evaluating, and participating in the development of Rucio. In 2018, the decision by the CMS collaboration to adopt Rucio for Run-3 marked a breakthrough for the community project. Other communities evaluating or deploying Rucio, to name a few, include the neutrino experiments DUNE and IceCube, the Belle II experiment, the gravitational wave experiments LIGO & Virgo as well as communities in the astro-physics domain, such as SKA, LSST, or EISCAT_3D. Even communities outside of physics, e.g., the EUXDAT project in the agricultural data domain are investigating Rucio.

Figure 2. Rucio Community Workshop, 28 Feb - 1 Mar 2019, University of Oslo, Norway.
Being an open-source software, Rucio is becoming an integrated part of the Open Science initiative. Current developments are aimed to integrate the system into Open Data and Open Access platforms such as zenodo. The long term strategy of Rucio focuses on the scalability of the system in the era of high luminosity LHC and to prepare the system for an area where massive data producing experiments from different sciences share common resources, such as research networks and storage systems. The integration of new infrastructures, especially High Performance computers, is a major objective in the development roadmap since this enables the utilization of these resources across the entire Rucio community. Another objective is extending the support for metadata with the integration of external data stores. Rucio is a central component for the implementation of novel data lake concepts that offer storage workflows to further optimize the data access patterns even across sites and to reduce storage costs.
Rucio started as a data management solution for the ATLAS experiment. It turned since into a community driven open source initiative in which large scientific communities within HEP and beyond strive to tackle the big data challenges of the next generation experiments in a common development project.
Further reading
-Rucio Website - https://rucio.cern.ch
-Rucio: Scientific Data Management, Computing and Software for Big Science (Springer) - https://link.springer.com/article/10.1007/s41781-019-0026-3