![]()
CLUE: A Scalable Clustering Algorithm for the Data Challenges of Tomorrow

The foreseen increase in luminosity and pileup at the High-Luminosity Large Hadron Collider (HL-LHC) [1] will challenge both the detector hardware and the reconstruction software. With higher pile-up, calorimeter energy reconstruction depends even more on pattern-recognition algorithms. These algorithms have to cluster together deposits produced by the same parent particle while rejecting any particle cross-contamination and noise as soon as possible.
The algorithm responsible for clustering calorimeter hits together must be both accurate and efficient, capable of handling the enormous number of hits recorded per event, and scalable to modern computing architectures.
Traditional clustering algorithms often fall short in this context. Their strictly sequential logic struggles with modern, data-heavy events and maps poorly to GPUs. Moreover, most ignore the physical weight of each hit, its deposited energy, which could guide clustering.
These limitations led to the development of CLUE (CLUstering of Energy) [2], an algorithm tailored to the unique requirements of high-granularity calorimeters. CLUE is a density-based, weighted clustering algorithm: it determines clusters based on both the spatial density of points and their associated energy values.
As shown in Figure 1, the algorithm proceeds in four main steps. First, it computes the local energy density for each hit by searching for nearby hits and weighting them according to their distance and energy. A hit that is surrounded by many energetic neighbours will have a higher energy density.
Next, each point is linked to the closest point with a greater local density within a maximum distance (nearest-higher). Subsequently, points without any nearest-higher are classified: those with a density above a given threshold become seeds, which act as cluster centres, while the others are marked as outliers. Finally, clusters are built by linking each point to its nearest-higher, leaving outliers not attached to any cluster.
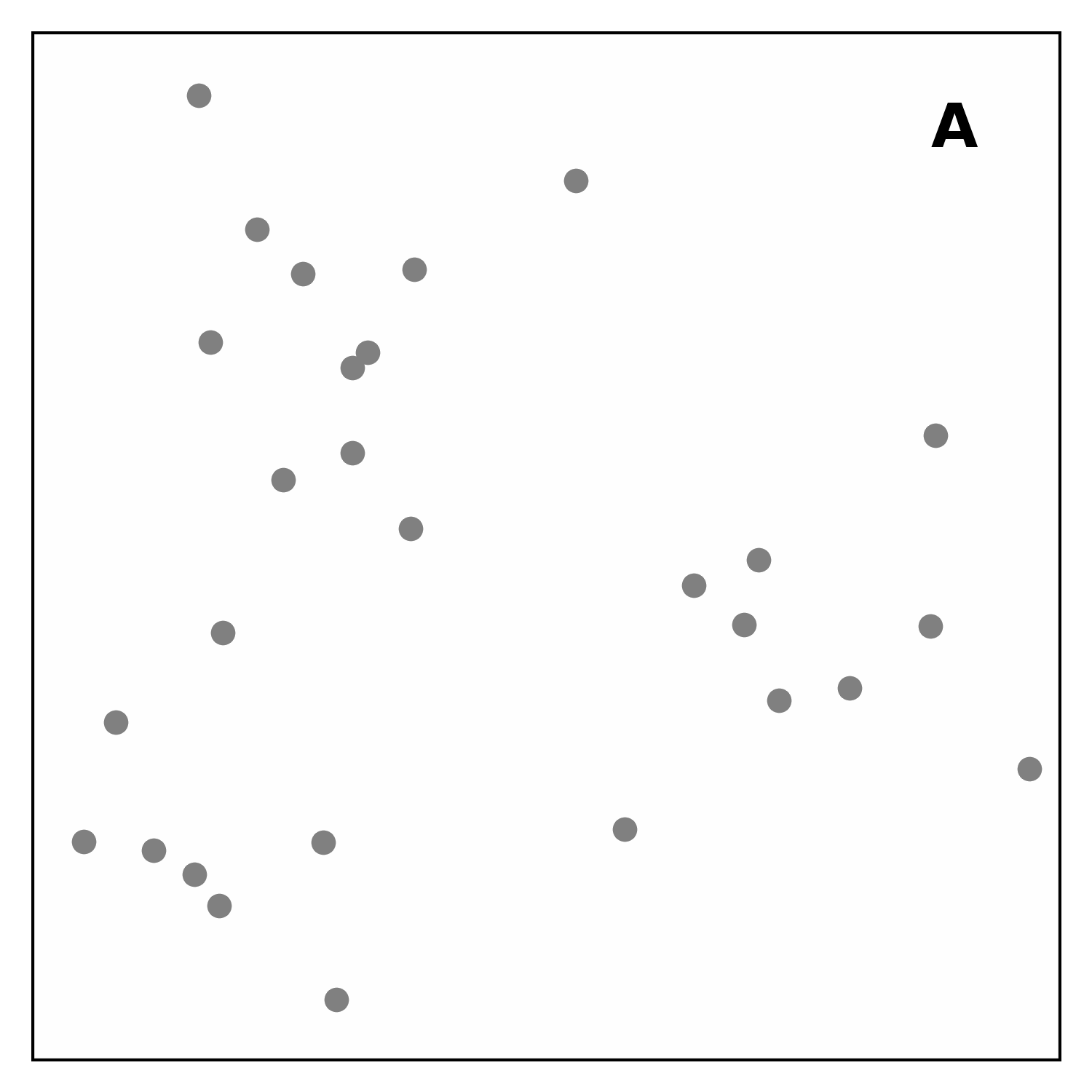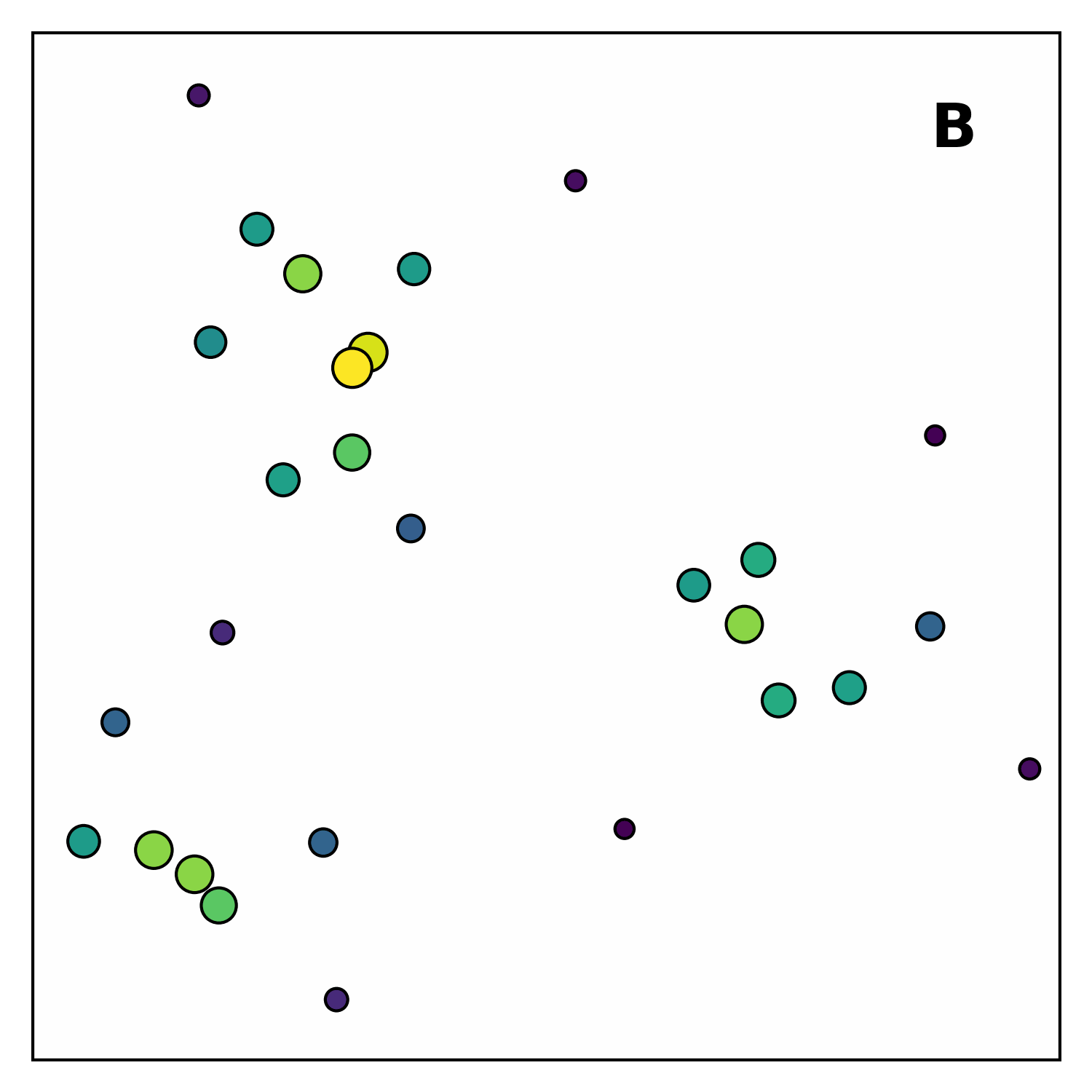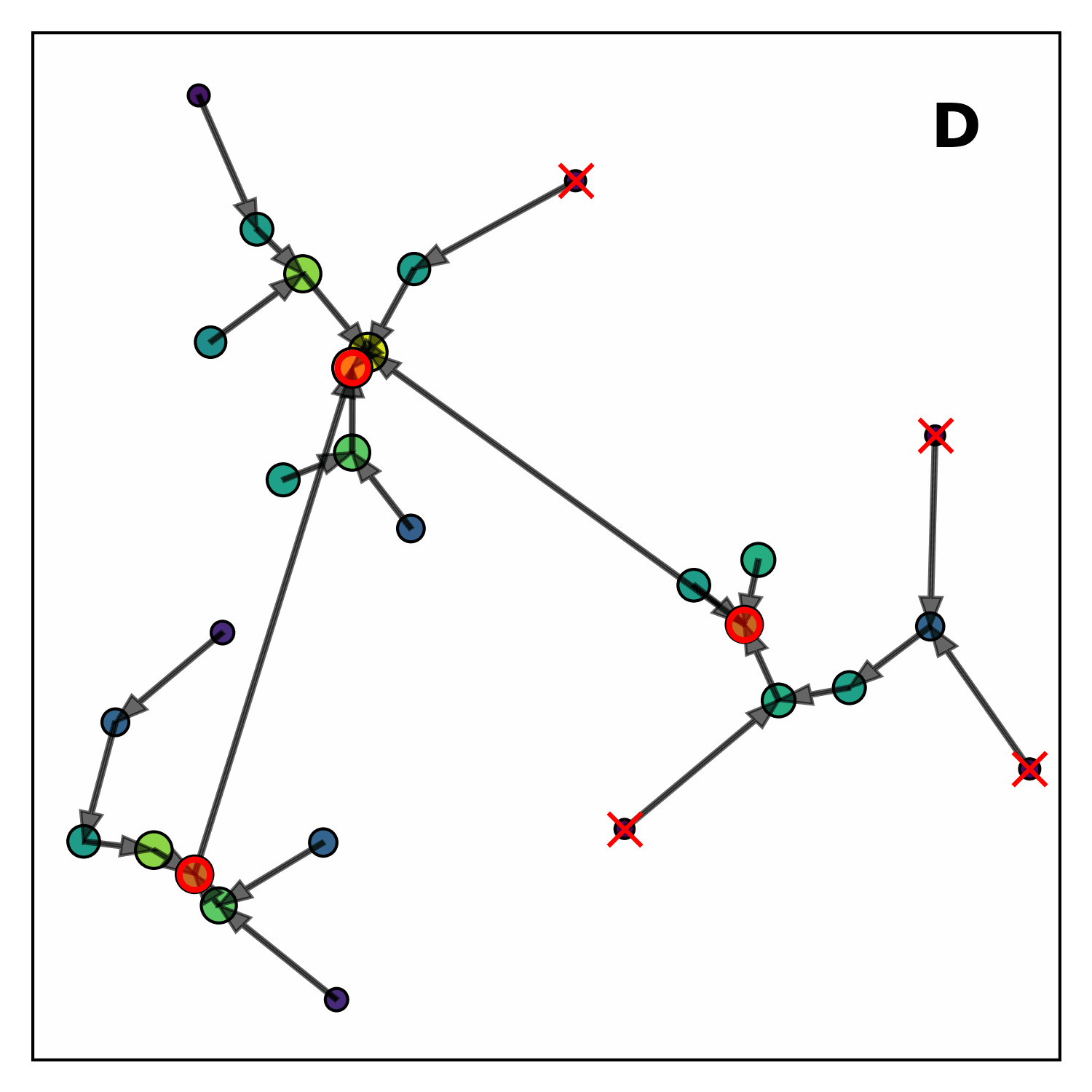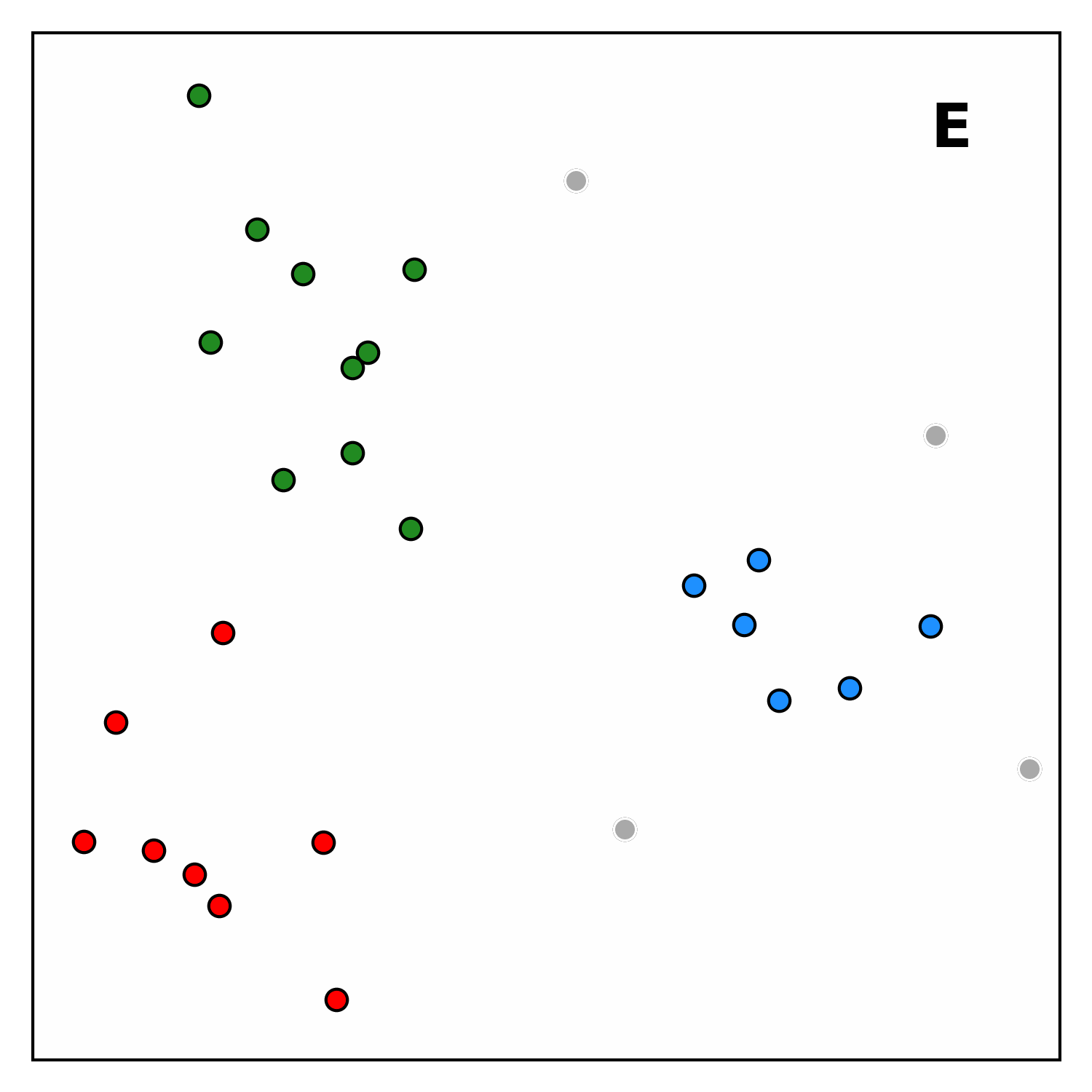
Each step is highly parallelisable and scales efficiently with the number of points, making CLUE well-suited for GPUs. Moreover, the data structures used by CLUE allow the clustering space to be partitioned efficiently, enabling near-linear computational complexity.
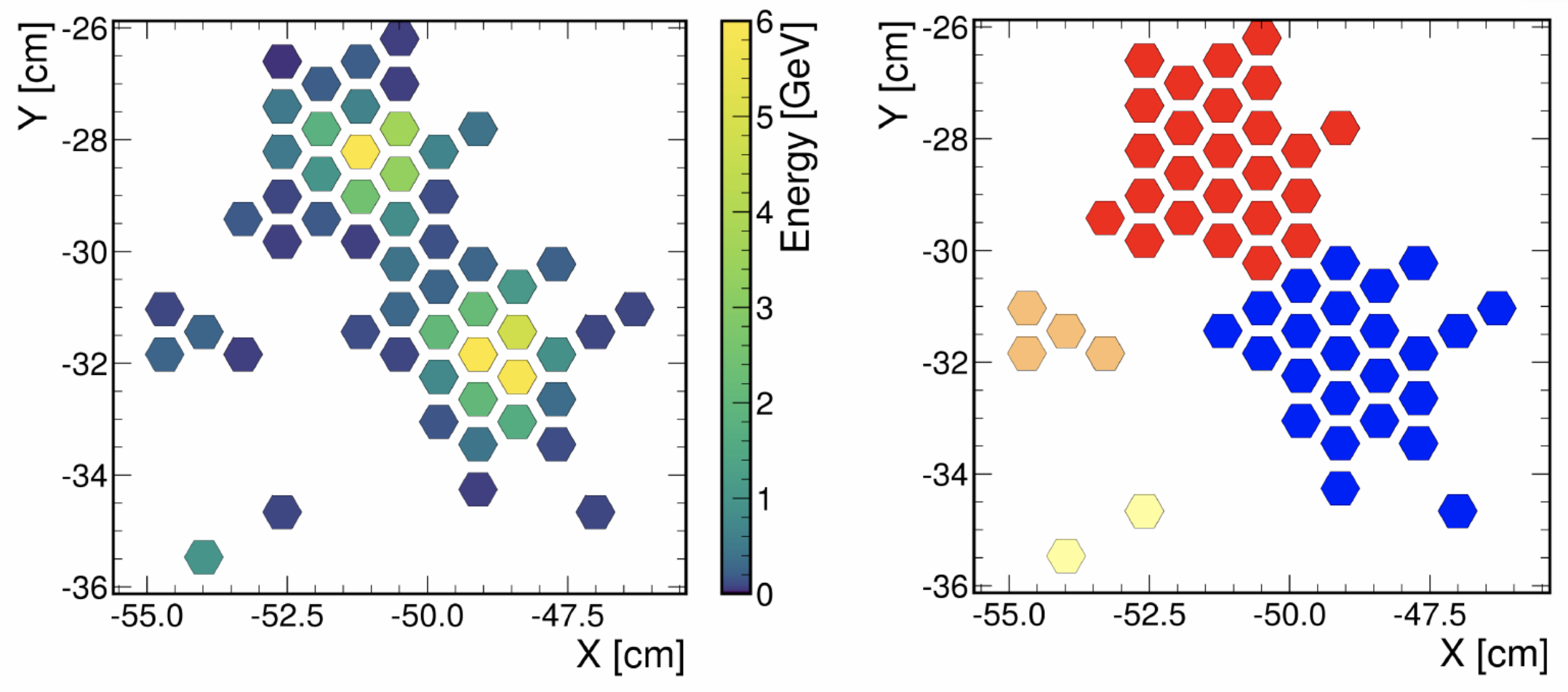
CLUE was originally developed for the High Granularity Calorimeter (HGCAL) [3], which will replace the CMS endcap calorimeters during LS3 [4]. HGCAL is composed of multiple layers of silicon and scintillator sensors that provide excellent spatial resolution. CLUE is first applied within each layer to form 2D clusters, as shown in Figure 2, significantly reducing complexity with minimal loss of information. A 3D version of the algorithm is then used to combine these 2D clusters into complete showers across layers.
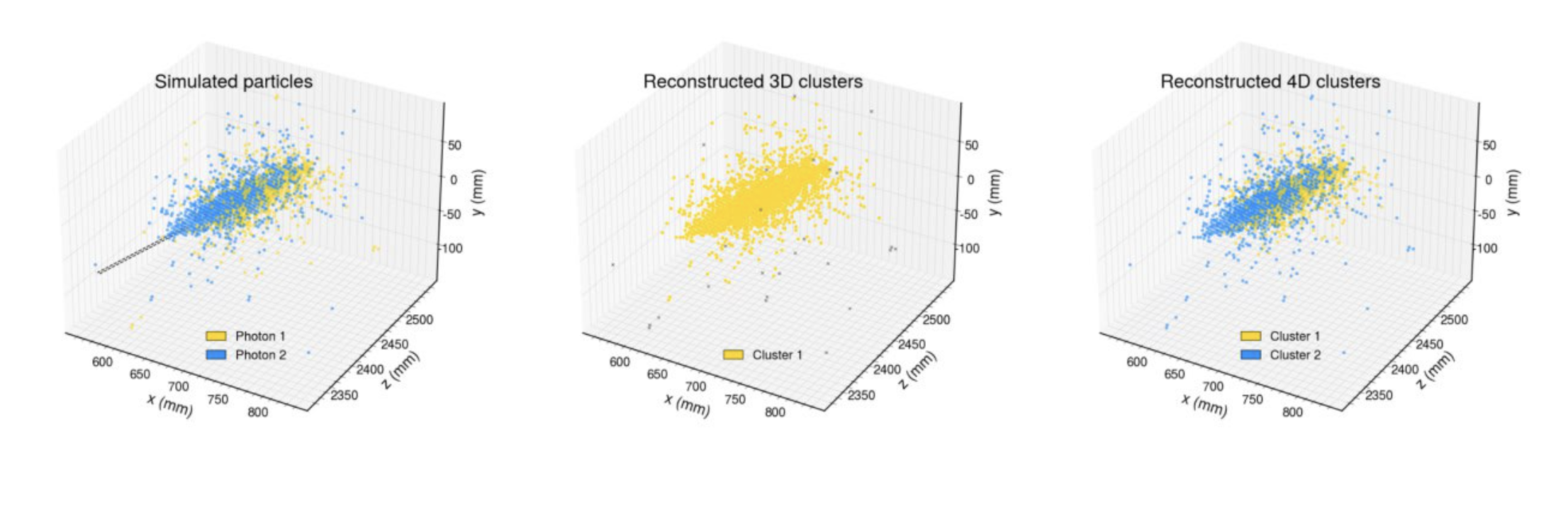
The CLUEstering library [5] was developed as a generic package that can be used in any High Energy Physics experiment and in fields beyond ours. Within the EP R&D programme, CLUEstering has been integrated into the Key4HEP [6] software stack within the Future Circular Collider (FCC) [7] project as a detector-agnostic algorithm, allowing its use across a wide range of simulated detector geometries. An example of how it can be used on 4D information (x, y, z, time) is shown in Figure 3.
Beyond high-energy physics, CLUEstering has also been applied in other fields, including the identification of forests by clustering of trees from satellite images, the identification of star clusters in astronomical images captured by CCD telescopes, and for the nearest neighbour search in latent space in machine learning applications [8]. These applications used the publicly available Python version of the CLUEstering library.
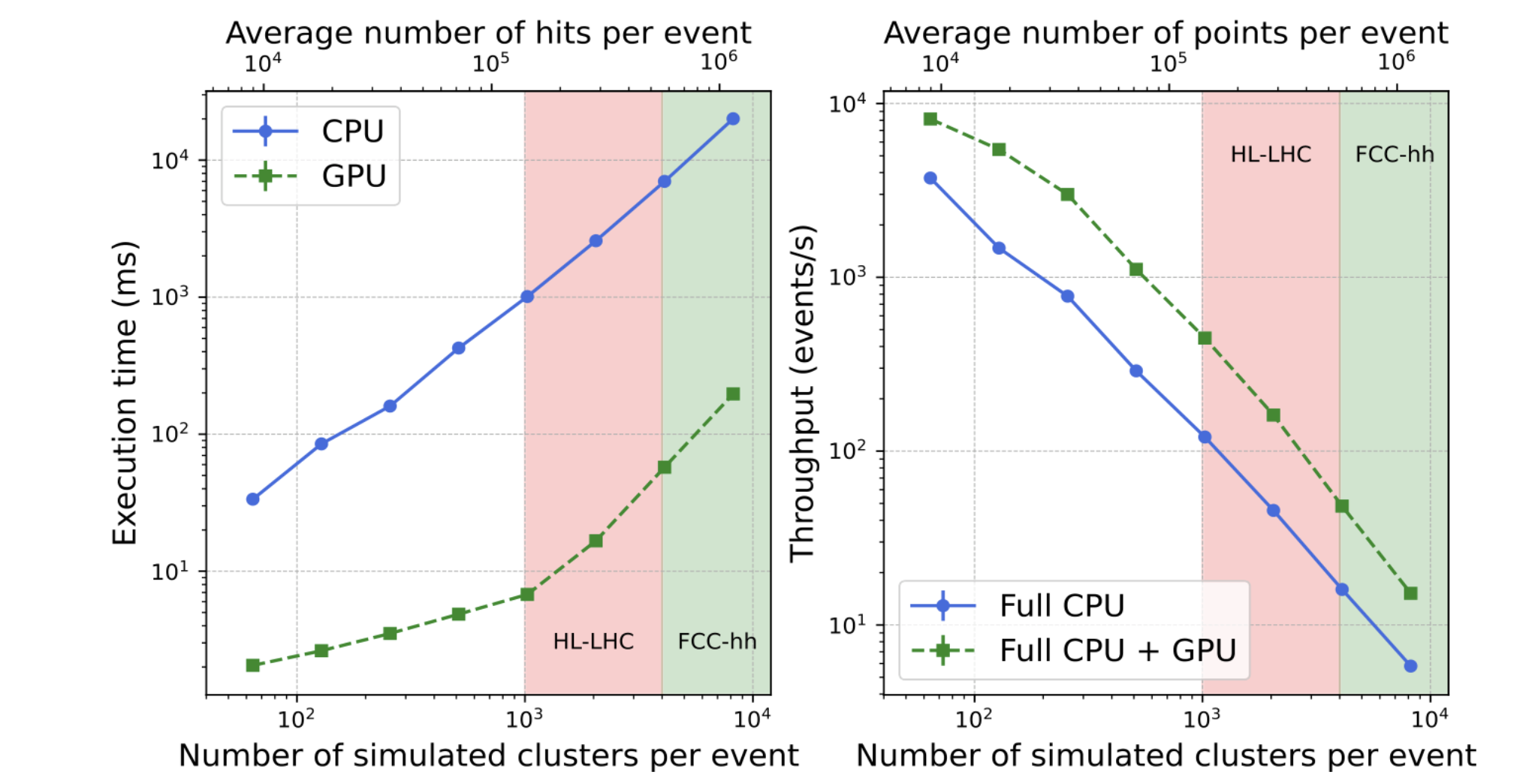
Thanks to its high level of parallelism and optimisation for GPUs, CLUE demonstrates excellent performance scaling. As shown in Figure 4, its execution time increases nearly linearly with the number of input points. The benchmarks show that the GPU can achieve a speed-up of about two orders of magnitude with respect to the CPU. Estimated ranges of occupancy for HL-LHC and FCC-hh are also indicated.
In conclusion, combining density-based logic with energy weighting, CLUE offers a highly efficient and scalable solution for large and complex multidimensional datasets. It is a powerful tool not only for high-energy physics experiments like those at the LHC, but also for a wide range of data-intensive scientific applications where speed, accuracy, and scalability are essential.
References
- https://arxiv.org/abs/1705.08830
- https://inspirehep.net/literature/2633578
- https://cds.cern.ch/record/2293646?ln=en
- https://iopscience.iop.org/article/10.1088/1748-0221/3/08/S08004
- https://gitlab.cern.ch/kalos/CLUEstering
- https://github.com/key4hep
- https://arxiv.org/abs/2204.10029
- https://indico.cern.ch/event/1360895/timetable/#79-final-scrum
- https://www.amd.com/en/products/processors/server/epyc/4th-generation-9004-and-8004-series/amd-epyc-9754.html
- https://www.nvidia.com/en-us/data-center/tesla-t4/