![]()
CMS Open data in use
This is a phrase in the CMS data preservation, re-use and open access policy, which was first approved seven and a half years ago. Now five years after the first release through CERN Open Data portal, and after three other successful releases, the latest of them last July, and with half of the CMS Run1 data available in the public domain it is a good moment to reflect on the interest and outcome that these data have generated.
The first publications using CMS Open data started to appear two years after the first release. It was with great excitement and pleasure that CMS physicists learnt about the first study ever done on public collider data: Exposing the QCD Splitting Function with CMS Open Data by Prof. Jesse Thaler and his group in MIT. Even more so as we, in the small CMS Data preservation and open access group, were very much aware that the instructions and documentation on the data usage were far from complete, a fact which was and still is reflected in the subtitle "Nice! But how do I analyse these data?" in our getting started instructions. We were and we are truly impressed by the work done by CMS open data users to understand the complex data and inherent complications due to their experimental nature.
Making data public does not make them any easier to analyse than they are for the members of the collaboration. We all know what it takes for a newcomer to get thoroughly familiar with experimental data: it usually takes a PhD. The first studies based on CMS Open data, however, have shown that using these data and getting new results based on them is possible if the analysis group is as dedicated to the work as analysis groups within the experiment are. Prof. Matthew Strassler nicely captures this in a recent post The Importance and Challenges of “Open Data” at the Large Hadron Collider. Providing open data, on the one hand, and making studies based on them, on the other hand, is expensive in personnel and time, but its value is clear: “[...]There is no guarantee, for instance, that any machine superseding the LHC will be built during my lifetime; it is a minimum of 20 and perhaps 40 years away. In all that time, the LHC’s data will be the state of the art in proton-proton collider physics, so it ought to be stored so that experts can use it 25 years from now. The price for making that possible has to be paid.”
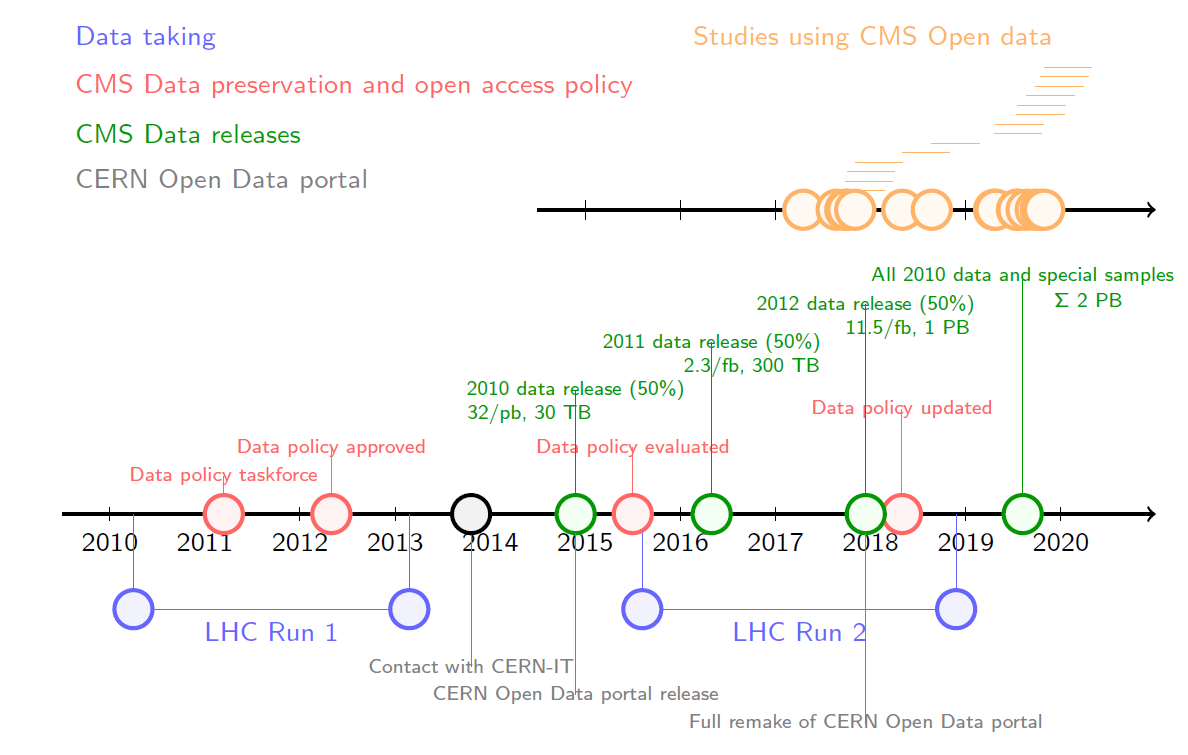
Since those first publications, the number of studies using CMS public datasets has been steadily growing, as shown in the graphics above. We can track them through citations to DOIs with which all datasets on CERN Open Data portal are delivered. The topics range from physics searches to analysis method testing and algorithm development. Real experimental data in real-life quantities can also be used to demonstrate the computing challenges as described by Clemens Lange's article. Furthermore, CMS Open data has been used in benchmarking ROOT, the tool, which has a foremost role in the analysis of any experimental particle physics data, as recently shown by Stefan Wunsch in a CHEP contribution. The CMS Open data comes with example work flows and these have been useful test cases for new services for analysis reproducibility such as ReANA.
The main worry often associated with the release of open data is the possibility that external users would get “wrong” results raising the need for additional work by the collaboration to correct them. This has not happened in these five years that open data have been available. Furthermore, authors of studies fully adhere to the open science paradigm and commonly share their code and derived data as done in the recent note Exploring the Space of Jets with CMS Open Data so that their expertise gained by using open data can be put into practice in the experiment.

Eric Metodiev from MIT showing the new methods developed by using CMS Open data in NeurIPS 2019 workshop on Machine Learning and the Physical Sciences in Vancouver, Canada
These studies and the questions we receive from the CMS Open data users are a great motivation for us to constantly improve our archival. Many missing features, necessary for full scientific usage of these data, have been brought to our attention through the support mail of the open data portal. These vary from technical questions when getting started with the virtual image in which the analysis can be done to details of the data selection and physics object reconstruction. Working on these reported issues, we have been able to add features to the portal records and improve the documentation. Frequently asked questions - and their solutions - have been added to the troubleshooting guide. In addition, external users have spotted missing files and mistakes, which we have been able to recover and correct in time.
We have a long to-do list to work through to provide a self-contained set of instructions for research use of CMS Open data. Recently, we asked CMS Open data users to provide their feedback that would help us set a priority list for improvements. Top of this list is to provide a complete enough analysis example, which walks the newcomer through different steps in the analysis of experimental data thus complementing the already existing examples. We have set that as a goal to reach before the first workshop for users of CMS open data, planned for summer 2020 at the LPC in Fermilab, to which we are looking forward with great excitement. As Jesse Thaler and Matthew Strassler put it in their note to the editor in Nature Physics, this exchange is a vital part of testing of CMS Open data archival: “[...] scientists can stress test archival methods; any deficiencies are easier to fix now than later”.
Besides their scientific use, CMS Open data are in wide use in education and outreach. Having the detailed analysis object data files on the portal together with simplified samples in csv format and an example code to produce such format, makes it straight-forward for anyone to use them in any educational context, from schools to university physics courses. In addition to already available simplified dataset, for example with double-lepton spectrum or the ready-made root files needed for the final plotting in the Higgs to four lepton analysis, anyone can easily produce a simplified dataset specific to a learning goal or context. A collection of Jupyter notebooks for handy use directly in a browser in SWAN for CERN users or in Binder free for anyone is available in a repository. A quick start to CMS open data is provided, as well as a notebook illustrating the Higgs to four lepton analysis. We warmly welcome further contributions to this collection in different languages.

An Open Data tutorial was held last August for the participants of CERN's International Teachers Programme. The tutorial was coordinated by Kati Lassila-Perini and two summer trainees, Linda Hemmann and Juha -Matti Teuho from Helsinki's Institute of Physics (Credits: Jeff Wiener).
To foster communication with the open data users, the CERN Open data portal team has now opened a discussion forum in https://opendata-forum.cern.ch/. We welcome all open data users to this forum and we hope it becomes a place for exchange of information not only between the users and the support team but also among the user community.
Many new efforts are ongoing in the domain of preserving data and analysis knowledge as reviewed in a recent workshop. LHC experiments are all profiting from common tools and services, which are now being developed at CERN. Different approaches such as reinterpreting searches based on preserved data products in ATLAS as detailed by Lukas Heinrich in his article about RECAST published in this newsletter, are all aiming at maximizing exploitation of LHC data.
The discussion has now started how to sustainably fund these efforts. For open data, the CMS experiment has lead the way, and we as data providers, the CERN Open Data portal team as a service provider, and the CMS Open data users have shown beyond any doubt that open science with preserved LHC data is possible. As summarized in the note to Nature Science by Thaler and Strassler: The public collider data complements the overall LHC research effort and full publication of the LHC experiments’ data is in the best interest of particle physics.