![]()
Deep learning and the quest for new physics at the LHC
With massive amounts of computational power, machines can now recognize objects and translate speech in real time. Deep-learning software attempts to mimic the activity in layers of neurons in the neocortex, the wrinkly 80 percent of the brain where thinking occurs. The software learns, in a very real sense, to recognize patterns in digital representations of sounds, images while it can also be used to analyse the data collected by the detectors of the LHC experiments.
The current Deep Learning hype is that given enough data and enough training time, it will be able to learn on its own. Could it also be the case that in the future it helps us to graph new ideas and concepts in high-energy physics? This may be an exaggeration of what the state-of-the-art is capable of doing for now and far from the actual practice of deep learning. However, it is true that Deep Learning over the past few years given rise to a massive collection of ideas and techniques that were previously either unknown or known to be untenable.
A key property of any particle is how often it decays into other particles. The ATLAS and CMS experiments at the LHC search for new particles and processes using head-on collisions of protons of extraordinarily high energy. Searches for rare processes and short-living particles are challenges by the required statistics and the noisy background that could hide signals of new physics. This challenges puts a need to explore how advanced machine-learning methods could apply to improve the analysis of data recorded by the experiments.
Presently the experiments select interesting events - at the level of the so-called High-Level Triggering - by reconstructing the trajectory of each particle using the raw data from the silicon layers of the inner tracker. Raw data from the detector are processed to obtain hit clusters, which are formed by nearby silicon pixels which have an electrical current value greater than zero. The cluster shape depends both on the particle, on its trajectory and on the module that has been hit. In that sense, track reconstruction by its nature is a combinatorial problem that requires great computational resources.
It is implemented as an iterative algorithm where each iteration apply five steps. In the seed generation track seed are created from hits in the internal layers of the detector based on a set of parameters. The seeds found in the first step are used for the track finding, which looks for other hits in the outer layers. After all the hits have been associated to the track the track fitting determines the parameters of the trajectory. The last step of the iteration is track selection, which is necessary because the previous steps could generate fake tracks. This steps looks for signals that denotes fake particles, like a large number of missing hits. Note that missing hits could be caused by different reason, like broken pixels or a region not covered by sensors. The previous steps are repeated in an iterative fashion, each time with different parameters for the seeding phase. Using this method it is possible to search for easy tracks first, eliminate from the successive searches the hits associated with the found tracks, and look for the more difficult tracks in the successive steps with a less dense environment.
As perhaps you can imagine, the main problem of this approach is the huge number of fake tracks generated during the seed generation and track finding. One of the most challenging and interesting applications of machine learning techniques is the study of jets originating from heavy flavour quarks (b/c “tagging”). Studying the particle tracks from these jets is crucial in searches for new physics at the LHC as well as the precise measurement of Standard Model processes. Starting with improved b-jet tagging techniques the method can also be applied in jets containing W, Z or top particles.
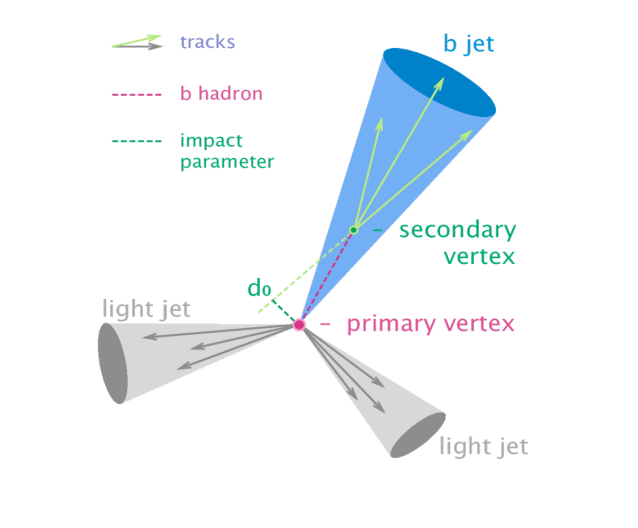
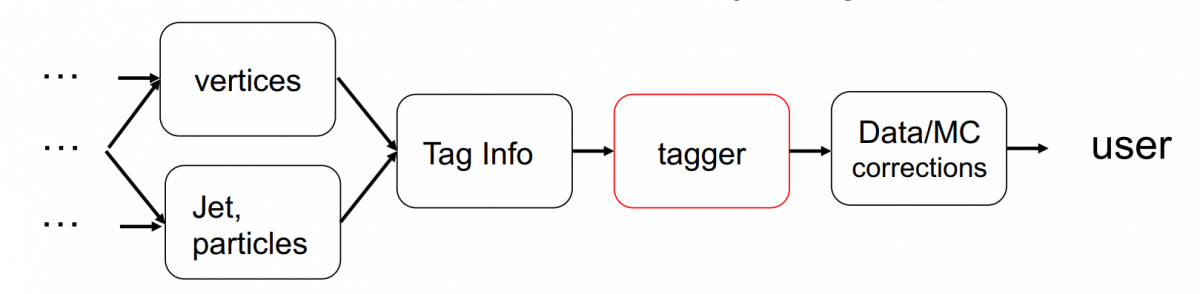
The reconstruction chain in jet tagging; the task is to identify the particles coming in a jet like (i.e. b-quarks as in the image above). Image credit: M. Stoye.
Markus Stoye, is leading this effort within the CMS collaboration. Already during his PhD in the University of Hamburg, he familiarized with the application of statistical and numerical techniques in high-energy physics and specifically in the alignment of the CMS tracker during which they had to ensure that 16.000 silicon sensors would be aligned with the detector. In the last 18 months he decided to apply deep learning techniques to tackle the challenges of studying the jets of particles produced at the LHC. The new generation of b tagging algorithms have shown incredible performance compared to previous b-taggers. Stoye explains: “A variety of b tagging algorithms has been developed at CMS to select b-quark jets based on variables such as the impact parameters of the charged-particle tracks, the properties of reconstructed decay vertices, and the presence or absence of a lepton.”
After an initial training period during which he familiarized himself with the concepts and available tools he decided to start building a group within the CMS collaboration and together with a small team they worked to implement the neural network techniques for b-tagging. Following the first successful results of the CMS tagger, that demonstrated significant improvement compared to previous taggers, the team grew and today there are about ten people working to push further deep learning techniques in the analysis of CMS data.
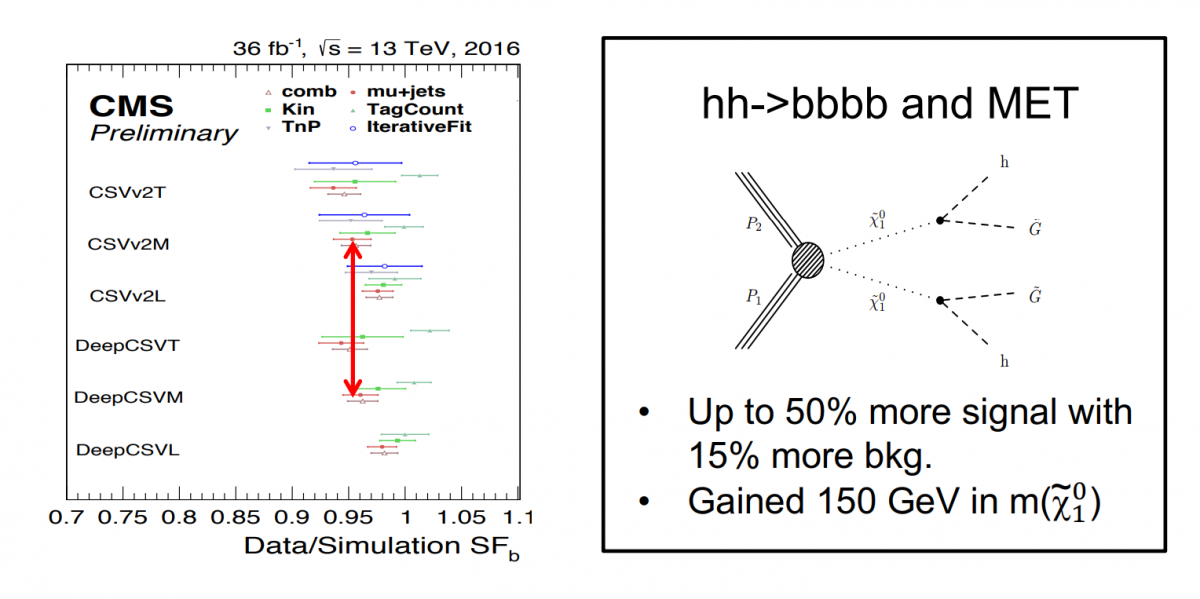
The right plot shows a comparison between the scale factors measured by different methods in ttbar events (Kin, TagCount, TnP, IterativeFit), the combined scale factors obtained from the muon enriched sample (mu+jets), and the combined scale factors obtained from ttbar and muon enriched samples (comb). Further information: here.
They currently design a neural network architecture that can do simultaneously the formerly independent steps that are followed in the analysis of jets, e.g. variable design per particle and track selection. Stoye explains: "The input to the deep learning algorithm are the constituents of the jet, all its particles and secondary vertices. These adds up to about 1000 features and if you use a general dense deep neural network you might have 10.000.000 to minimize in your optimization and in the customized structure is only 250.000 as based on some assumptions - correct in the physics sense - you can reduce the complexity". In contrast to other algorithms, the new approach uses properties of all charged and neutral particle-flow candidates, as well as of secondary vertices within the jet, without a b-tagging specific preselection. "The neural network consists of multiple 1x1 convolutional layers for each input collection, their output is given to recurrent layers, followed by several densely connected layers. So far, in our simulations, this algorithm outperforms the other taggers significantly, in particular for high-pt jets, which could lead to improved sensitivity in searches for new physics with high energetic b jets in the final state."
“In this process one has to understand both the available architectures as well as the physics problems. We input pretty complete information about the particles to the algorithm and gradually the neural network starts becomes able to figure out itself what is most important for the analysis. ” and continues: “We know that we have better tagging following the copious efforts of the past nine months. Thanks to the neural network technique there is an acceleration in the way we improve on these fields compared to the past though this is not to undermine all past efforts and the way in which they pushed our understanding.“
As a next step, the team plans to develop ways to reduce systematic uncertainties. Stoye explains: “Presently there are different approaches on that within data science and this is an aspect that I am presently focusing. This is a major branch of research in data science in general and is called domain adaptation while it will be a major step in developing new techniques”.