![]()
Designing gas transport parameters for future HEP experiments

Fig. 1 Large experimental systems at LHC, comprising various gaseous detectors covering thousands of m2, providing tracking and triggering for muons.
Given their large areas and cost effectiveness, particle physics experiments rely heavily on the detection of charged and neutral radiation with gaseous detectors. The operational gas mixtures used in large LHC experiments have been the outcome of an extensive R&D process to reach the stringent performance required.
Freons are very commonly used in large muon and RICH systems. Since 2014, an EU “F-gas” regulation has come into force, with the aim of limiting F-gases, that will be reduced to one-fifth of 2014 sales by 2030 in line with Net Zero 2050 goals. Given their environmental impact, and the uncertainty of availability and price of these F-gases, it is fundamental to prepare a mitigation plan for the future of LHC and non-LHC experiments. A complete synergy of the community ranging from simulations and experimental measurements of the properties of gas mixtures is mandatory towards designing next generation of experiments at both the high energy and the high intensity frontier.
To instrument large sensitive areas, gas detector technology will remain unchallenged in several applications for tracking and triggering, muon systems, RICH and TPC readouts wire chambers, resistive plate chambers and micro pattern detectors. To meet the physics goals of planned experiments and future facilities, these devices need to be further optimised towards high rate capability, fast timing, improved space resolution and high ion mobilities for applications at future upgrades and colliders. Future experiments at HL-LHC and FCC, will require mandatory use of environment friendly gases to limit the impact of greenhouse gases (GHG)s. In addition, the volumes of present and future detector systems range from 10 to 100 m3, thus posing a big environmental threat in case of leaks to the operation of gas systems of the future.
During the nineties ('90s) a concerted effort was made to create a repertoire of interaction cross sections of gases in a range of energies that turned out to be very useful in first designing the gas mixtures to be used at the LHC experiments and then comparing the experiments with the simulations of gas transport parameters. A large amount of publications on transport parameters followed during the years 2000 onwards with data both on simulations and experimental studies that consolidated operations.
However, a large range of gases has been constrained due to the renewed sensitivity to climate change and environment, resulting in new rules and policies for environment safety vis-á-vis gases containing GHGs for the large experiments at CERN and elsewhere/other laboratories around the world.
Looking to the future, we need to create a similar compendium of the simulations and experimental measurements for “green” gases and gas mixtures which also qualify in terms of the requirements for tracking and triggering in ever increasing hostile environments. There is a lack of cross sections and precise data for molecular gases which are required for the future gas detector systems.
The industrial sector has been developing green alternatives and these new gases are the subject of an intense R&D for new detector gas mixtures. However, there are at least two difficulties to overcome: how to mitigate the problem for detectors currently in use and the stability of the new eco-gases. The most critical implications are for the large detector systems currently operational at the LHC experiments. Detectors and electronics are installed and access to them is very difficult as well as it is not possible to replace any component. In this case, the new eco-mixtures will have to adapt to existing constraints. On the contrary, the next generation of detectors must be completely designed around new eco-mixtures.
To address these issues, a mini-workshop aiming to consolidate the ongoing efforts and future direction towards studying operational behaviour of possible improvements and novel gases, gas mixtures was held in the RD51 community, including a worldwide participation of over 216 participants: https://indico.cern.ch/event/1022051/timetable
Rob Veenhof and Piet Verwilligen chaired the session on cross sections, simulation techniques, and status of measurements of experimental gas transport parameters respectively. Large experiments at CERN operating with F gases were discussed in a session chaired by Davide Piccolo. The sessions were followed by a discussion session leading to future possible collaboration. Roberto Guida chaired the session on studies of “ECOGAS” for the Resistive Plate Chambers.
The gaseous detector community has developed several strategies, presented at the workshop, to reduce or optimize the GHG emissions in particle detection: optimization of current technologies, gas recuperation and alternative gases. The “optimization of current technologies” is mainly upgrading the present gas recirculation systems and improvements in the control of gas parameters. The “gas recuperation” is necessary when it is not possible to recirculate 100% of the gas mixture and the part of it has to be recovered. The ALICE experiment has implemented a gas recirculation system for the RPC muon trigger. Gas recuperation systems are operational for the CF4 component of CMS CSC and LHCb RICH2 detectors. A complex gas recuperation system for the C2H2F4 (R134a) of the RPC detectors is under study. All these interventions together with a big effort to reduce detector leaks should be able to limit the emissions of GHG by the time the R&D to find an ecological alternative would be successful.
The second point is related to the stability of the new eco-gases: they have a low global warming potential mainly because of their very limited stability in the atmosphere due to reactions with water and/or decomposition due to UV light. Unfortunately, these conditions are also present in ionization gaseous detectors. Indeed, for example, it has been already measured how RPC detectors operated with the new HFO are producing about 4 times more Fluoride with respect to the standard R134a based mixtures (Figure 1). The presence of larger quantities of impurities could increase the long-term risk of detectors ageing and this topic should be the subject of dedicated studies in the next few years.
Concerning the RPC detector technologies (RPC, MRPC and TOF), several groups from Turin, Frascati, Rome, CERN and GSI presented results based on HFO mixture pure or with the addition of neutral gases (i.e. Helium and CO2) for lowering the high voltage working point. There are still difficulties related to the slightly large pulse charge and streamer probability but encouraging results have been obtained for instantaneous performance in the laboratory (Figure 2) and during test beam in presence of LHC like gamma background radiation (Figure 3). However, there is still a long way to go before a new gas mixture could be considered for the current experiments and ongoing studies will help clarifying the situation.
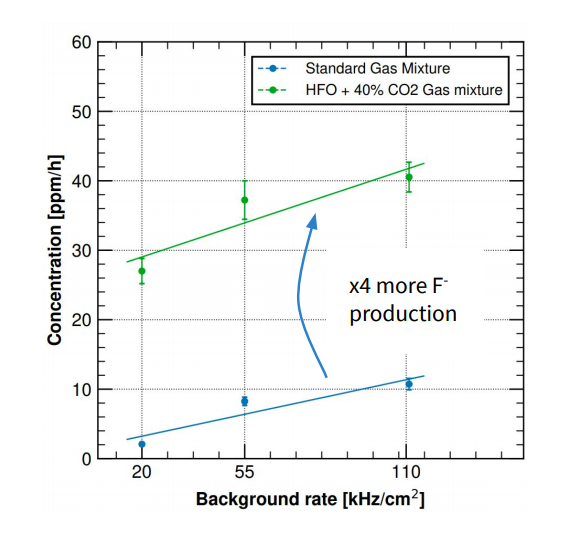
Figure 2 Fluoride production in irradiated RPC detector operated with standard R134a and HFO based gas mixtures (G. Rigoletti – CERN).
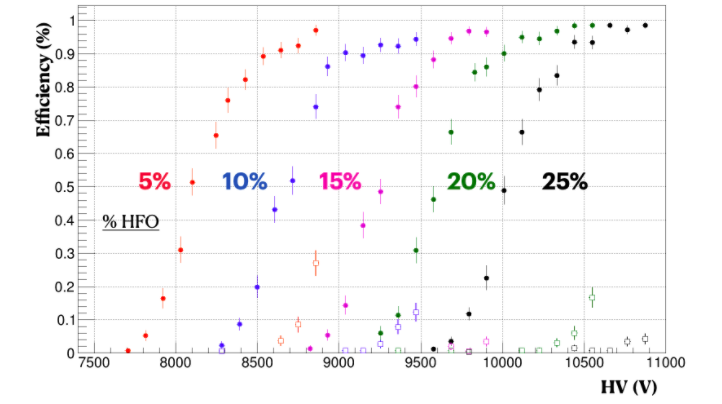
Figure 3 RPC detector efficiency to cosmic ray with mixtures containing different HFO/CO2 concentrations (G. Proto – Rome).
Very interesting is also the case of the Cathode Strip Chamber (CSCs) detector, where CF4 is currently used to prevent the formation of deposits on the wire. In this case, the easy decomposition of the new HFO could likely be a positive factor. However, a recent test highlighted an increase of dark current in a detector operated with HFO. Further studies are expected to shed light on this issue and how to address it. An alternative for an immediate mitigation, seems to be the possibility to decrease the CF4 concentration in the currently used gas mixture.
For ionization gaseous detectors, the possibility to work with sealed detectors has always been an interesting and challenging line of research. Encouraging results have been presented during the meeting. For the moment this could be an alternative to be further explored, in particular for experiments subject to very low radiation levels (i.e. cosmic rays) spread over large surfaces.
Several options exist also for RICH detectors. New Silicon PMs can reduce the chromatic error and increase the photon yield. This could allow replacing CF4 (used in the LHCb-RICH2) with CO2. Studies are ongoing in this direction. In the case of the LHCb-RICH1, C4F10 could be replaced with hydrocarbons like C4H10 which would then call for addressing the flammability risk.
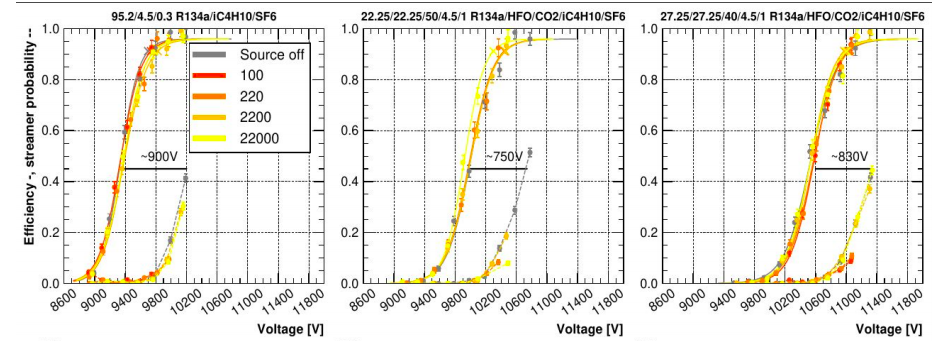
Figure 4 RPC detector efficiency to muon beam in presence of LHC-like background radiation with mixtures where part of the R134a has been substituted by HFO (G. Rigoletti – CERN).
S. Biagi who has been the main architect of optimising cross-sections of various gases from measurements outlined that gaseous detectors can be divided into categories depending on whether they need high precision electron-gas cross-sections (drift chambers, TPC, MWPC. MPGDs) or with lower precision cross-sections (RPC, streamer and Geiger counters). E. Carbone presented the efforts of the LXCAT (Electron and ion scattering), a community-based project for storing, sharing and evaluating data needed to model non-equilibrium low temperature plasmas, which started in 2009. The project consists of a library of datasets, since different applications can need different datasets. Every user can easily create a new database and upload data (electron- and ion-neutral scattering cross sections) or download cross-section data to perform online calculations with BOLSIG+ (Boltzmann equation solver), plot and compare swarm parameters. A proposed idea is to transcribe all cross sections available in Magboltz [https://cern.ch/magboltz and https://cern.ch/nebem] into LXCAT thus increasing the synergies between the different efforts. Their measurements have been used for populating most of the LXCAT databases.
Future challenges lie ahead and the workshop demonstrated the readiness of the community to address them through innovative and collaborative R&D projects. The volumes of detector systems, for the next generation of detectors, must be completely designed around eco-mixtures. Obtaining funding for the needed work is challenging as immediate breakthroughs are not evident that could facilitate creation of cross-sections of molecular gases that are used in high energy physics detectors, essential for using eco-gases. Despite the challenges, this workshop confirmed that a vibrant cadre of physicists is committed to taking the field forward. A follow-up workshop is planned to take place in about one year.