![]()
Navigating the Data Tsunami: CMS Prompt Data Processing and Distribution in Run 3

Improvements implemented in the CMS trigger and data acquisition systems before the start of Run 3 LHC in 2022 have enabled an increase in both the event rate and the volume of useful data collected by the CMS detector, thereby broadening its physics reach. This advancement posed a significant challenge for the CMS Tier-0 and data management services, which are tasked with the prompt processing and global distribution of data to Tier-1 computing sites for future reprocessing and long-term storage, as well as to Tier-2 sites to facilitate analysis by the Collaboration.
During Run 3, the trigger rate was increased from 1 kHz to 2.6 kHz for the data that requires immediate processing. In addition, CMS captures up to 3 kHz of so-called parking data, which contains the same event content but typically requires more time for analysis and can be processed later. The other major type of data, known as scouting, has a trigger rate that can reach up to 30 kHz. Scouting employs online data reconstruction, offloading a significant fraction of computations to GPUs. This shift frees up CPU resources, enabling such high trigger rates. Scouting data is stored in a final format for analysis, significantly reducing the event size by a factor of 100, albeit at the cost of limited detector resolution and object reconstruction efficiency.
In the first year of Run 3, the CMS experiment significantly boosted its data collection rates. Compared to Run 2's final year, it achieved a 50% increase, reaching a peak of 10 GB/s – nearly double the rate achieved in late 2018. This record-breaking performance continued throughout 2023. For proton collisions, the average combined data rate hovered around 6.5 GB/s, with bursts reaching 20 GB/s during the heavy ion run.
The data collected by the detector is reformatted and tightly compressed to minimize storage space requirements. Concurrently, the first step of data processing, involving the calibration of detector data, is executed promptly. This step must be completed in time for the reconstruction of all collision events – a process that is automatically initiated 48 hours after data collection and utilizes up to 50,000 CPUs available to CMS at CERN.
The delayed processing of parking data presented significant challenges, notably due to the single tape copy available and the considerable time needed to retrieve this volume of data for processing. To mitigate these issues, CMS has made efforts to promptly process both regular and parking data, relying exclusively on CERN's computing resources to date. For the 2023 heavy ion run, European Tier-1 sites were also mobilized to accelerate the processing of all heavy ion data. This collaborative effort led to the deployment of 100,000 running CPUs, enabling the completion of all heavy ion data processing within three weeks after the end of data collection.
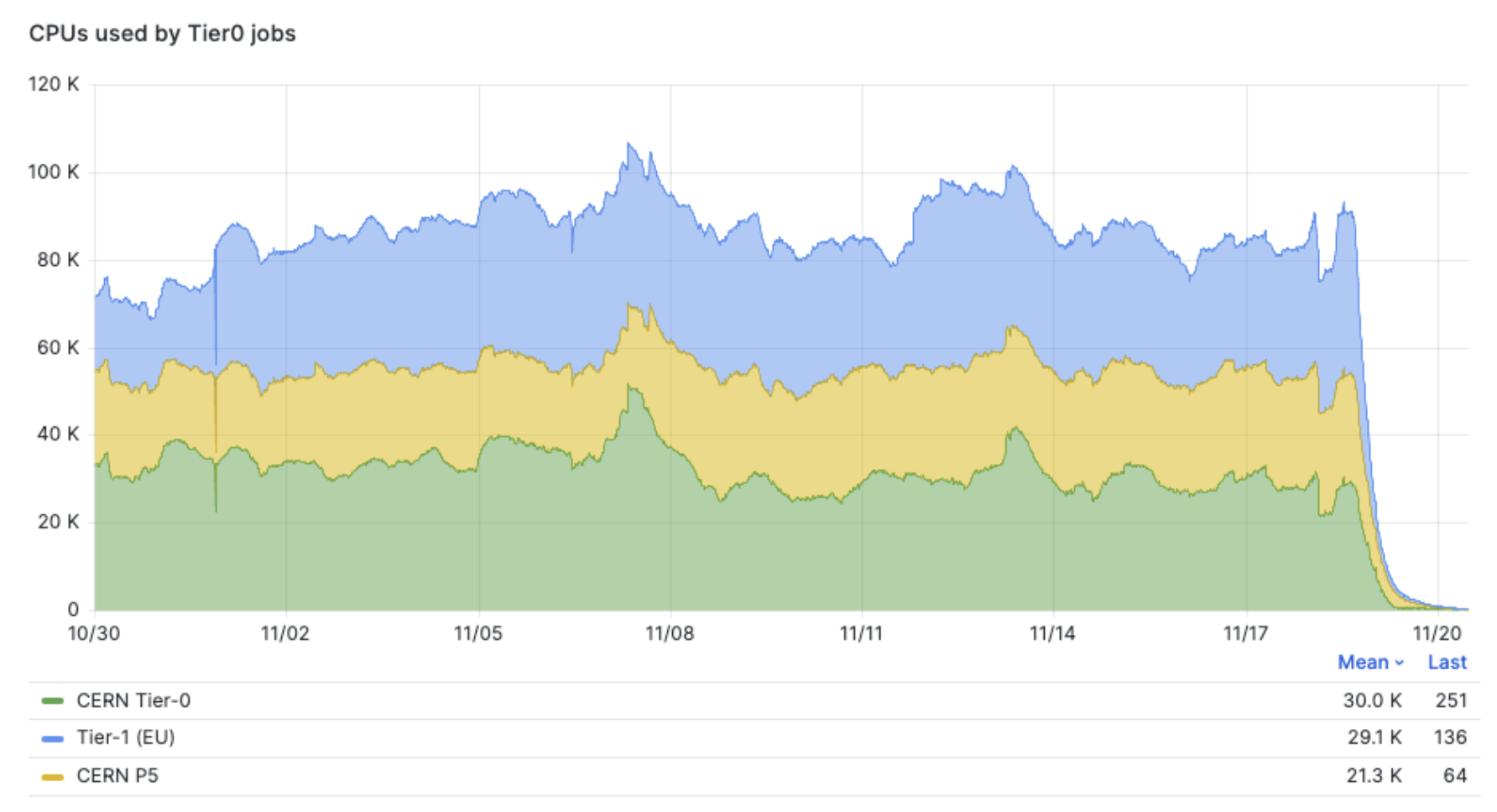
Figure 1: CPU utilization for heavy data processing at the end of the heavy ion run in 2023.
For every dataset collected by CMS, approximately twice as much simulated data is produced. Moreover, each collision event undergoes multiple re-analyses using improved and refined reconstruction techniques to maximize the precision of physics analyses they are used in. This leads to a rapid data accumulation, particularly on tape storage, which holds the last copy of all produced data. To ensure sufficient space for new data and its corresponding simulations, CMS conducts annual data deletion campaigns. With hundreds of active physics analyses utilizing various data processings and Monte Carlo simulations, it is not straightforward to identify samples to delete.
In 2023, CMS executed the largest deletion campaign in its history, removing approximately 85 PB of data from magnetic tapes to make room for Run 3 collisions. This action resulted in the deletion of roughly 25% of the data stored on tape.
The rest of Run 3 will likely remain challenging as the CMS collaboration tries to maximize the physics potential of the detector by introducing new triggers and/or extending the scope of scouting and parking data. In 2024, we're adding new single-muon parking and scouting datasets, stretching the limits of the trigger, data acquisition, processing, and distribution systems. These updates move us closer to the High Luminosity LHC data-taking conditions. They stimulate developments that will better prepare us for Run 4, while simultaneously gathering high-quality data that will remain valuable for many years to come.