![]()
Update on CernVM-FS
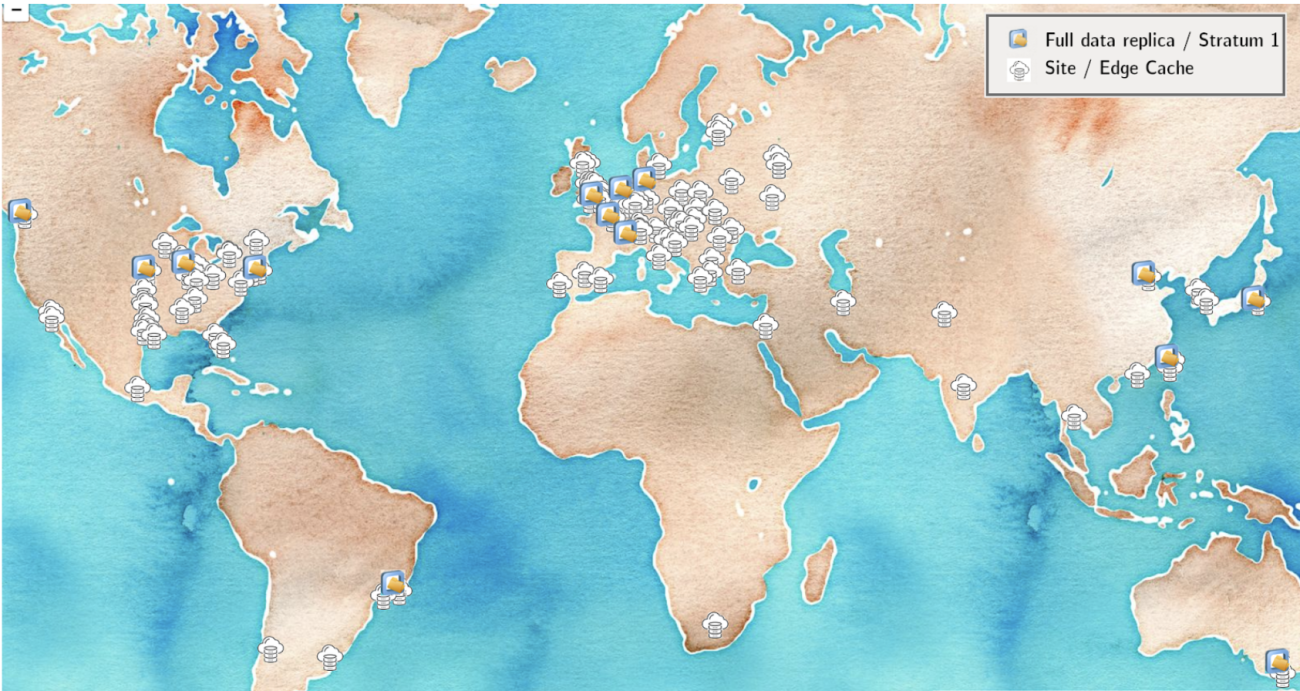
Fig. 1: Map of CVMFS cache instances. The tiered cache model is one of the techniques that helps to efficiently deploy software on /cvmfs to computing sites all over the world.
Anyone who has ever used experimental software on CERN's computing infrastructure is likely to be familiar with CernVM-FileSystem (CVMFS) - even if only from the /cvmfs/... part of file paths encountered in many 'Getting Started' guides. What lies behind the acronym is a specialized solution developed by the SFT group in the EP department to a particular problem in the distributed computing model of High-Energy Physics. Experiments require software to read, process and analyze their data. It comes in the form of shared libraries, scripts and other small files structured differently from experiment data. Distributing these files along with experiment data may result in inefficiencies and, in the worst case, cause an overload of the storage element due to numerous compute nodes simultaneously trying to access it, idling the computing resources. By utilizing CVMFS for software deployment, this issue can be avoided, thanks to its sophisticated caching that allows many compute jobs to use only one subset of an experiment's software. Also, contrary to traditional package managers, CVMFS will only download the parts that are actually read.
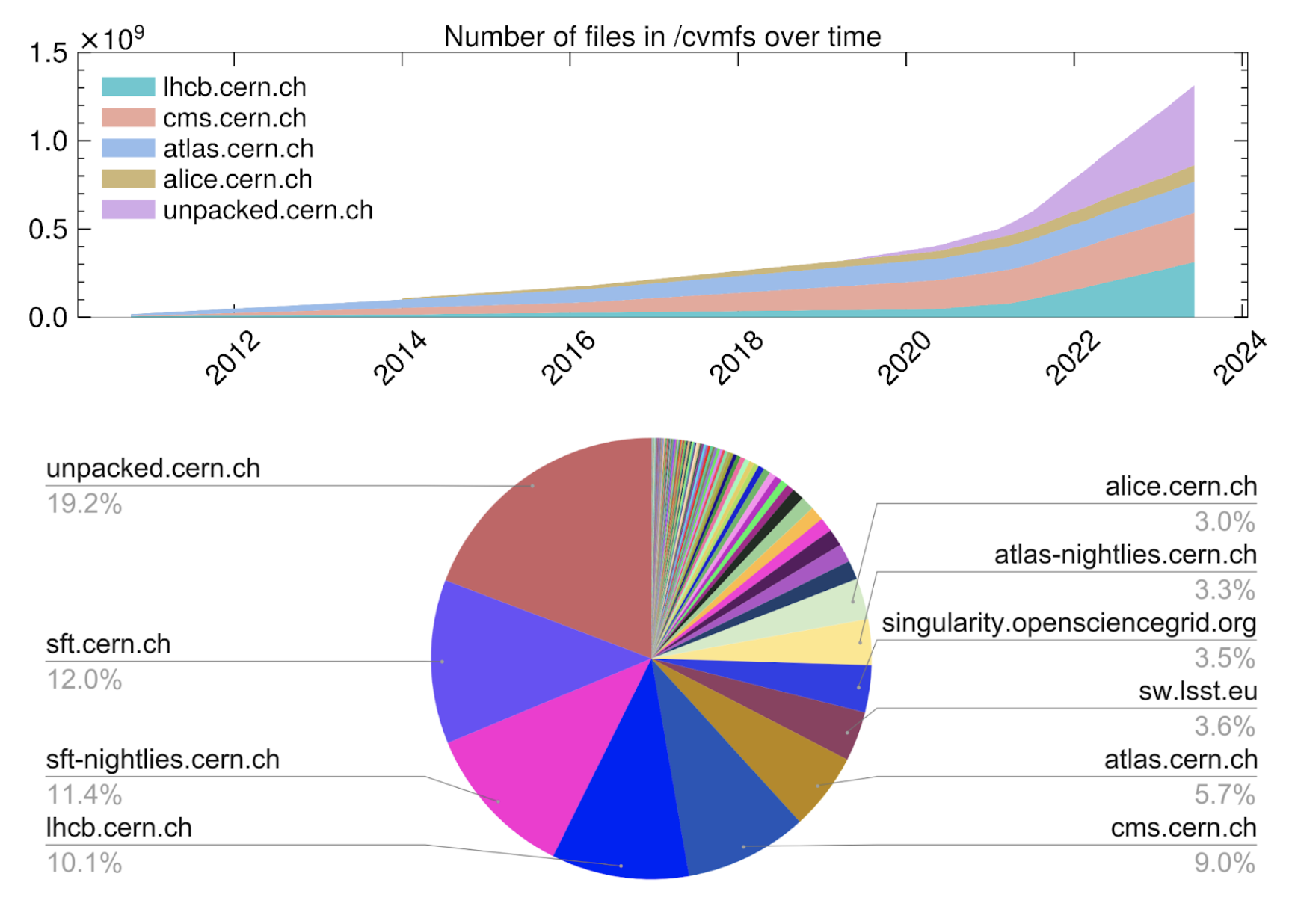
Fig 2: CVMFS repositories by size. More than 200 software and storage repositories are publicly accessible via /cvmfs, corresponding to many small collaborations from several fields of science. The LHC experiments are the biggest users, and have intensified their usage in recent years especially via unpacked.cern.ch, which can efficiently distribute container images to the grid.
So far, CVMFS has been used successfully for many years by all CERN experiments and many others outside the HEP domain, such as the LIGO, LSST, and EUCLID collaborations from astrophysics, bio- and medical science, and even by some private companies. As computing requirements evolve, the upcoming HL-LHC upgrade will be challenging for the entire software ecosystem, including CVMFS. Infrastructure growth and increasingly complex software stacks with larger files put CVMFS to the test.
Thanks to the engagement of CERN Knowledge Transfer that resulted in the additional contributions and funding from private trading company Jump Trading, the CVMFS development team was able to address the specific issues encountered while running CVMFS under a very high load on their internal High-Performance Computing infrastructure. This served the immediate interest of the company and was beneficial to the whole community of CVMFS users. As a result of the collaboration with Jump Trading, a number of noteworthy performance improvements were implemented and will be available in the upcoming CVMFS release version 2.11. In particular, the introduction of symlink caching helps to noticeably speed up many common operations using files on CVMFS - more details on these developments can be found in the recent CHEP conference presentation [2]. This is a prime example of a CERN Knowledge Transfer success that deserves to be highlighted.
The CVMFS was initially developed as an essential part of the CernVM appliance. This customizable virtual machine has played an important role in the transition of LHC computing to emerging virtualization technology that started a decade ago. Following the further evolution of technology, CernVM was adapted to containerization technologies such as Docker and Kubernetes. The CernVM team plans to release an updated version of their images, CernVM 5, in 2023. This version will support cloud computing and container engines, allowing for improved efficiency, startup times, and stability for container workloads.
CVMFS has become a critical component of the computing infrastructure for many experiments. The CVMFS development team is investing significantly into ensuring the performance and stability of the system, and it is grateful for the many collaborations and contributions from colleagues at the WLCG sites, the operators in CERN's IT department, the CERN Knowledge Transfer group and the industry partner Jump Trading. With their help, CVMFS should be able to support computing at even the most demanding HL-LHC scale and beyond.
Further Reading
[1] CernVM-FS website: https://cernvm.cern.ch/fs/
[2] "CernVM-FS at Extreme Scales" - Talk at CHEP 2023: https://indico.jlab.org/event/459/contributions/11483/
[3] "Large-scale data processing with CVMFS at Jump Trading" - CERN Computing Seminar: https://indico.cern.ch/event/1247861/