![]()
Machine learning ushers in a new paradigm for particle searches at the LHC
Searching for physics beyond the Standard Model (BSM) is a major part of the research programme at the LHC experiments. Nearly all of these searches pick a signal model that addresses one or more of the experimental (e.g., dark matter) or theoretical (e.g., the hierarchy problem) motivations for BSM physics. Then, high-fidelity synthetic data are generated using this signal model. These signal events are then often combined with synthetic background events to develop an analysis strategy which is ultimately applied to data. An analysis strategy requires a proposal for selecting signal-like events as well as a method for calibrating the background rate to ensure that the subsequent statistical analysis is unbiased. Many searches provide `model-independent' results, which means that the cross-section of the signal is unconstrained while the event selection and background estimation are still strongly model-dependent.
These search efforts are constantly improving and are important to continue and expand with new data. However, it is also becoming clear that a complementary search paradigm is critical for fully exploring the complex LHC data. One possibility for the lack of recent/new discoveries is that new physics is hiding due to the model dependence of our current search paradigm. Model independent searches for new particles have a long history in high energy physics. Generic searches like the bump hunt assume little about the signal and have been used to discovery many new particles dating back at least to the discovery of the rho meson, and used continuously since, including recently in the discovery of the Higgs boson by the ATLAS and CMS experiments. While generic, the bump hunt is not particularly sensitive because it usually does not involve other event properties aside from the resonant feature. More differential signal model independent searches have been performed by D0, H1, ALEPH, CDF, CMS, and ATLAS. The general strategy is to directly compare data with simulation in a large number of exclusive final states (bins). Aside from the feature selection, these approaches are truly signal model independent. The cost for signal model independence is a strong background model dependence and there may also be difficulty with signal sensitivity if there are a large number of bins.
Machine learning offers great potential to enhance and extend model independent searches. In particular, semi-, weak-, or un-supervised training can be used to achieve sensitivity to weak or complex signals with fewer model assumptions than traditional searches. Supervision refers to the type of information provided to the machine during training. An unsupervised algorithm provides no labels (the prototypical example is clustering). Weakly supervised methods provide complete but noisy labels and semi-supervised methods provide partial label information (e.g. rely partially on simulation, which provide labels).
Anomaly detection is an important topic in applied machine learning research, but high energy physics challenges require dedicated approaches. In particular, single events often contain no useful information - it is only when considering a statistical ensemble that an anomaly would become apparent. This is a contrast between anomaly detection that is common in industry (`off manifold examples') and those that are the target of searches in high energy physics ('over densities'). In analogy, if you see a flying elephant, you know it is an anomaly (off manifold). However, how would you know if there are more elephants than usual at a particular watering hole (over density)? The latter requires understanding the probability density of Standard Model physics in order to determine if there is evidence for something new. Furthermore, high energy physics data are systematically different from natural images and other common data types used for anomaly detection in applied machine learning. In order to test the resulting tailored methods, it is essential to have public datasets for developing and benchmarking new approaches.
LHC Olympics 2020 Challenge
This problem was the motivation for the LHC Olympics 2020 challenge. The name of this community effort is inspired by the first LHC Olympics that took place about a decade ago before the start of the LHC. In those Olympics, researchers prepared `black boxes' of simulated signal events and contestants had to examine these simulations to infer the underlying signal process. The black boxes were nearly all signal events and many of the signatures were dramatic (e.g. dilepton mass peaks) and all were findable with simple analysis procedures. While this was an immensely useful exercise for the community, we are now faced with a new reality where new physics is rare or at least hard to find and hence characterizing the BSM properties will not be our biggest challenge.

Olympics-style intersecting rings with representative images from the four LHC experiments and the LHC accelerator.

Participants at the ML4Jets2020 workshop at NYU in January 2020, which hosted the Winter LHC Olympics.
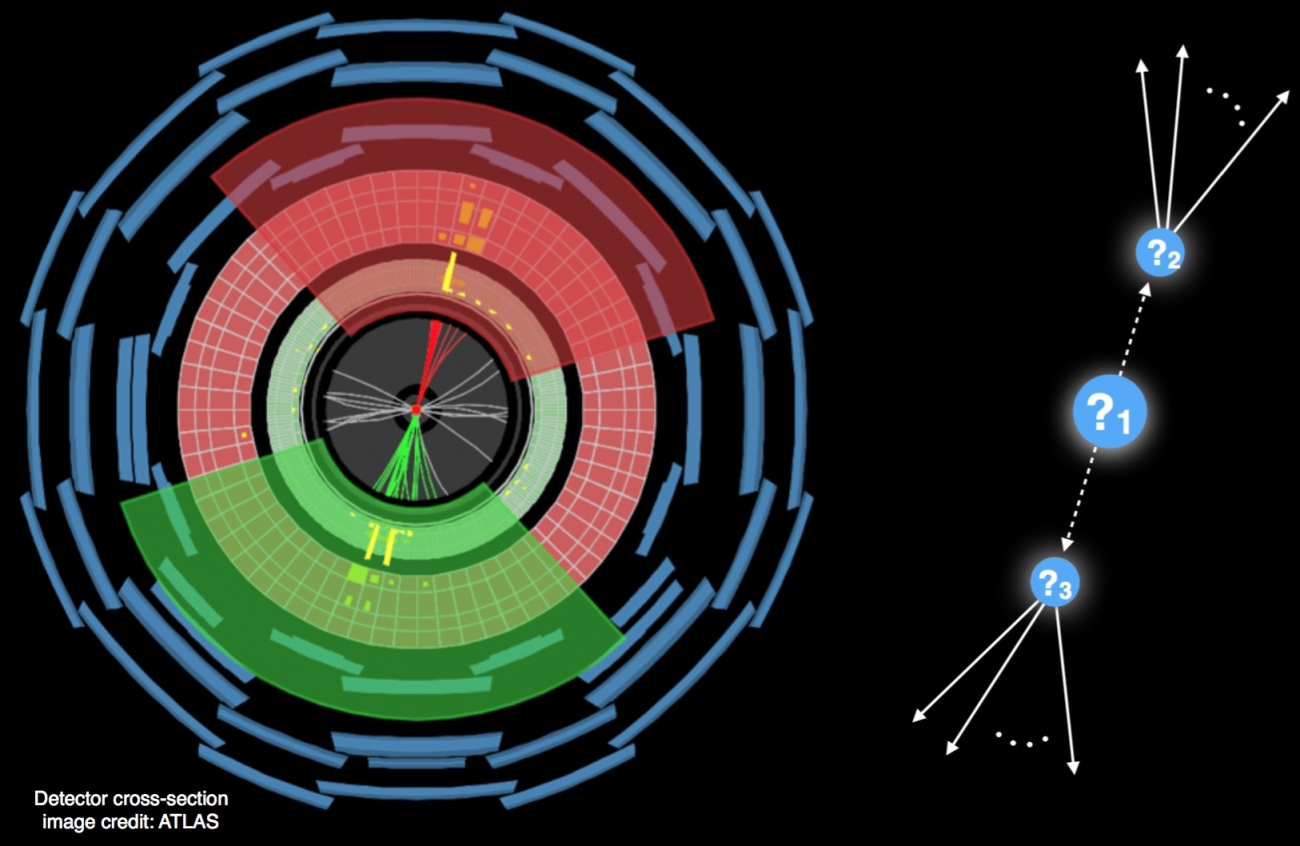
The LHC Olympics 2020 challenge was also composed of black boxes. However, contrary to the previous Olympics, these boxes are mostly filled with SM simulations. The goal of the contestants was to determine if the boxes were hiding new physics and then to characterize any anomalies. Contestants were provided with a list of hadrons per simulated event (all data hosted on CERN’s Zenodo) allowing them to test methods that can process low-level event information. As already stressed, calibrating the background prediction is an essential aspect of BSM searches and so this search is restricted to a high energy hadronic final state where sideband methods can be used to estimate the background. As with real data analysis, contestants were provided a simulated dataset (with no anomalies) in addition to the black boxes in order to aid them in the development and refinement of their methods. Results were presented at the Winter and Summer Olympics 2020 competitions. Well over one hundred researchers participated in these events, with over a dozen teams submitting their results..
The first black box contained a new heavy particle that decayed into two other new (less) heavy particles, which then decayed into quarks. This signal topology is shown below. A mass hierarchy between the X,Y particles and the Z’ resulted in a dijet-like topology where the decay products of the X and Y particles were well-collimated into single hadronic jets with two-prong substructure. The amount of signal injected was such that it would not be a significant bump in the inclusive dijet mass spectrum. A plot that shows the reported Z’ mass from all of the teams is shown below. During the Winter Olympics, contestants bravely presented their results before knowing the correct answers were revealed! Multiple teams were relatively close to the right mass. The teams were not ranked as all methods are an important contribution to this growing research area. However, two submissions clearly stood out. A strategy based on conditional density estimation from a team of cosmologists at Berkeley (George Stein, Uros Seljak, Biwei Dai, He Jia) reported results that were accurate and precise for all signal parameters. A second team of experimental particle physicists from Johns Hopkins University (Oz Amram and Christina Suarez) used a combination of weak and unsupervised methods and also arrived at nearly the right Z’ mass and cross section within uncertainty.
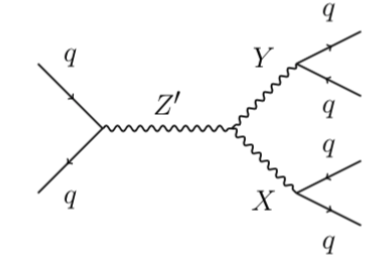
A Feynman diagram for the signal injected into black box 1.
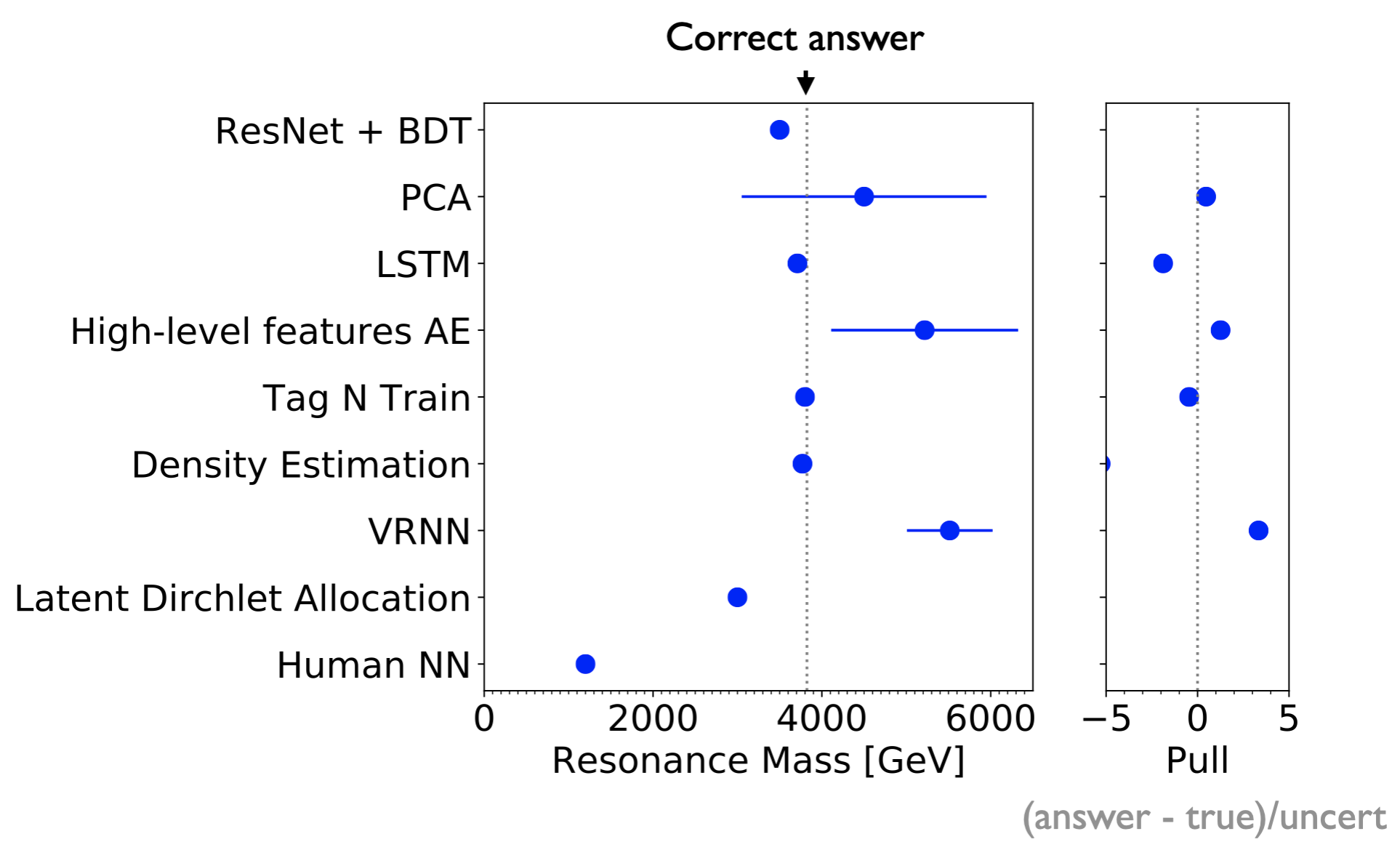
Partial results for resonance mass in black box 1. The order is arbitrary and not all teams reported an uncertainty. Briefly, some of the acronyms are: BDT = boosted decision tree, PCA = principal components analysis, AE = autoencoder, NN = neural network. More details in this talk.
Black boxes 2 and 3 were much more difficult. In fact, black box 2 has no signal at all! Many groups reported a signal in this black box, but there was clearly no strong consensus as was the case for the first black box. The signal in black box 3 had two decay modes and was designed to be insignificant if only one of the two modes were identified. None of the teams were able to find this signal - a result that clearly demonstrates that we need new methods!
While many of the talks presented at the Winter and Summer LHC Olympics were focused on the LHC Olympics datasets, there were also a variety of other talks related to anomaly detection. For example, some new anomaly detection techniques were discussed, but not yet applied to the LHC Olympics dataset. An updated “living review” of new techniques hosted by the CERN machine learning group can be found here. The first collider result of weak supervision applied to anomaly detection using the CWoLa hunting technique was also presented during the Summer LHC Olympics. A mix of experimentalists and theorists participated in the Olympics workshops and we should expect new method proposals and collider data results that have built off of ideas discussed at the workshops in the near future. Additionally, a community paper that documents the LHC Olympics challenge is being prepared and will be available in early 2021.
A data-driven revolution has started with machine learning as its catalyst. We are well-equipped to explore the complex LHC data in new ways with immense potential for discovery. The Run 2 data collection is over, but our exploration of these precious collisions in their natural high dimensionality is only beginning. This LHC Olympics has been a starting point for a new chapter in collider physics that will produce exciting physics results from the current datasets as well from the datasets of the future at the LHC and beyond.
The author would like to thank Gregor Kasieczka (Hamburg) and David Shih (Rutgers) for the fruitful collaboration that resulted in the LHC Olympics.