![]()
The Phase-2 Upgrade of the CMS Data Acquisition system

Even though Run-3 data taking has only just started, the preparations for the next phase of the LHC physics programme are well under way. Just like the LHC, during LS3 many of the LHC experiments will receive significant upgrades.
In order to maintain its excellent physics performance under the increased instantaneous luminosity of the High-Luminosity LHC, the CMS experiment aims at an improved detector resolution, with a fully redesigned inner and outer tracker and a new new high-granularity end-cap calorimeter, as well as the addition of timing information to the detected physics objects. The new outer tracker will also provide tracking information to the first-level trigger.
Following the present established design, the CMS trigger and data acquisition system (DAQ) will continue to feature two trigger levels, with only one synchronous hardware-based Level-1 Trigger, consisting of custom electronic boards and operating on dedicated data streams, and a second level, the High Level Trigger (HLT), using software algorithms running asynchronously on commercial computing hardware and making use of the full detector data to select events for offline storage and analysis. The completely redesigned Level-1 trigger system will make use of tracking information and particle-flow algorithms to select events at a rate of up to 750 kHz (to be compared with a maximum Level-1 accept rate of 100 kHz for Phase-1) to maintain the efficiency of the signal selection at the level of the Phase-1 performance, while enabling or enhancing the selection of possible new physics leading to unconventional signatures.
The DAQ system is then tasked to provide the data pathway and time decoupling between the synchronous detector readout and data reduction, the asynchronous selection of interesting events in the HLT, their intermediate or temporary local storage at the experiment site, and the transfer to Tier-0 for offline permanent storage and analysis.
From the DAQ system point of view, the upgrade of the detector and Level-1 trigger, and the increased accept rate, will result in the need to support a vastly increased throughput. The event size increases to approximately 8.5 MB, which, at an expected trigger rate of 750 kHz, translates into an overall data throughput in excess of 50 Tb/s. (I.e., a 30-fold increase with respect to the current system.). The architecture of the Phase-2 CMS DAQ (see the figure below) represents a judicious evolution of the current system, taking into account the experience gained with its different incarnations since the start of operations in 2008. The on-detector front-end electronics sends the physics data to off-detector back-ends over radiation tolerant optical links (lpGBT and versatile Link+) developed at CERN. The back-end boards, implemented as independent cards hosted in ATCA crates in the CMS service cavern, govern the communication with the front-ends and forward the received physics data via point-to-point optical links to a common DAQ board: the DAQ and Timing Hub (DTH400).
The DTH400 in turn aggregates the data over a full orbit of the LHC, and then transmits them over a commercial data-to-surface network to the computing centre, located in a surface building at the LHC Point 5. There, in a compute cluster composed of commercial CPU and GPU nodes, the High Level Trigger reconstructs the collision data and selects events for further analysis at an approximate rate of 10 kHz. These events are stored locally, before being transferred to the CERN computing centre for offline reconstruction and permanent storage.
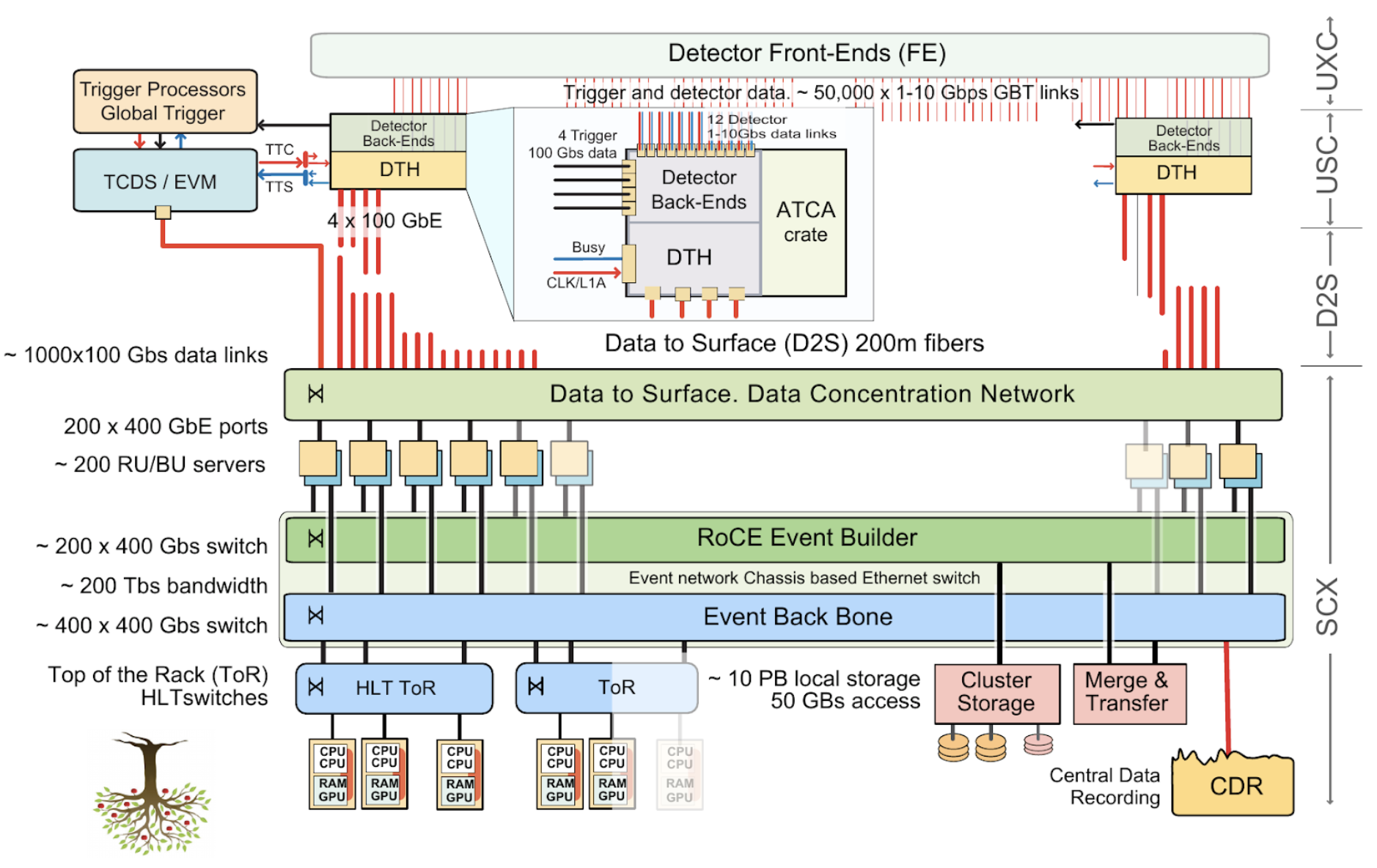
Figure 1: Principle architecture of the CMS Phase-2 DAQ.
Unified detector-DAQ interface: the DTH400 and DAQ800 custom ATCA boards
The DTH400 is a custom ATCA board used to interface the back-end crates to the central trigger and synchronisation system, the central DAQ system, as well as the CMS network for control and monitoring. It hosts two interlinked units: one dedicated to clock distribution and data-taking synchronisation, and one dedicated to the DAQ functionality. Each of these units is designed around a Xilinx VU35P FPGA. This FPGA was chosen for its built-in high bandwidth memory, which is required for the DAQ unit to provide sufficient data buffering in going from the LHC-synchronous back-end realm to the asynchronous world of the commercial networks and compute nodes.
In terms of custom hardware, the main deliverables of the DAQ project are the DTH400 and its companion board, the DAQ800. The latter provides no trigger/synchronisation functionality but is capable of twice the output bandwidth and can be added to back-end crates that require more data throughput than the DTH400 can provide.
The DTH400 has been entirely designed at CERN by the EP-CMD and EP-ESE groups, and its development started in 2017. Since then, three preliminary versions have been produced. Several independent projects have developed subsets of the DTH400 functionality, such as the managed Ethernet switch that bridges the boards in the crate to the CMS experiment network.

Figure 2: The DTH400 board prototype-2 together with the companion Rear Transition Module (RTM) housing the embedded controller.
The latest version of the board combines all prototyping and development efforts. It adds a rear transition module to the main (front) ATCA board, to hold an on-board controller based on a Xilinx Zynq ‘multiprocessor system-on-chip’. This version is set to become (with some minor modifications) the final one.
One key feature of the DTH400 is its ability to distribute precision timing to all the boards in the same ATCA shelf via the shelf backplane. A precision time reference is required by the upgraded sub-detectors that provide timing information. The clock quality is characterised in terms of phase noise and the corresponding RMS jitter. The phase noise spectra of the 40 MHz LHC bunch clock and the 320 MHz transceiver reference clock signals distributed to all slots over the backplane were analysed and the worst case jitter for the 40 MHz (320 MHz) clocks showed an RMS of 4.9 ps (3.7 ps). On a mock-up clock distribution chain, a front-end recovered bunch clock with a jitter of σRJ < 5 ps is achieved, where the most stringent sub-detector requirement is σRJ < 10 ps.
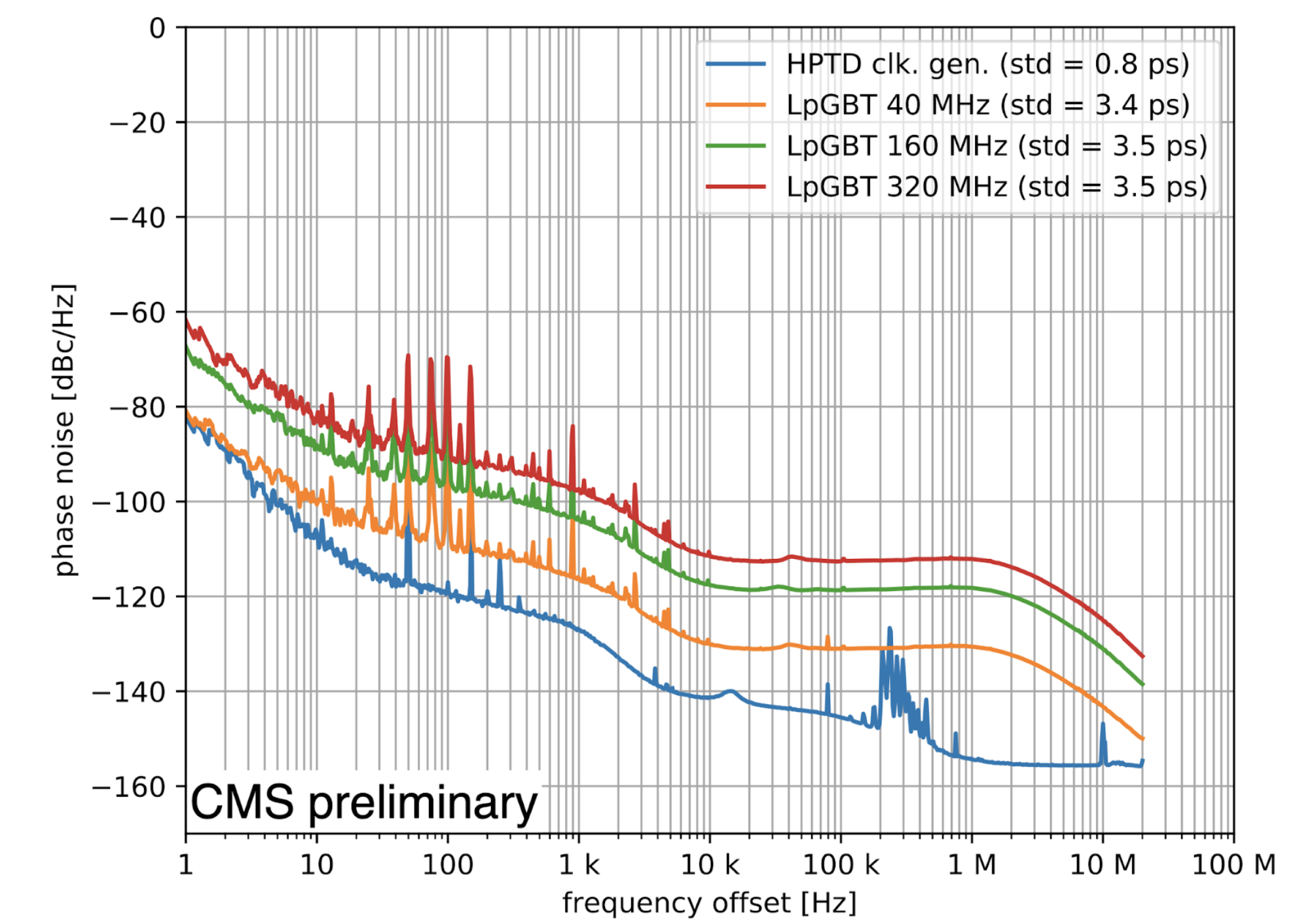
Figure 3: Phase noise spectra of the front-end clock recovered by an lpGBT ASIC in a mock-up of the Phase-2 timing system. Spectra are shown for three different recovered clock frequencies (top three curves), used by three different CMS subsystems, compared to the HPTD reference clock generator (bottom curve) developed by EP-ESE. A phase noise spectrum represents a frequency decomposition of the noise in a clock signal. The integral of the spectrum indicates the corresponding random jitter RMS.
The DTH400 will be produced in a small pre-series in 2023 for use in the commissioning of the sub-detectors and DAQ, along with a first prototype of the DAQ800 board. The final production will take place in 2025, ahead of the start of LS3 when the boards will have to be installed in the experiment.
Upgrade of the DAQ infrastructure
The DTH400 uses five QSFP28 optical devices to transmit the physics data to the surface computing centre using the standard 100 Gb/s Ethernet protocol. Physically, the data are coarse wavelength division multiplexed (CWDM4) for transmission, to enable the optical signal to cover the distance from the underground service cavern (USC) to the surface online computing centre (OLC). Order of 1200 new single-mode optical fibres will have to be installed between the USC and OLC to provide the necessary data-to-surface bandwidth.
The online computing centre itself will be refurbished and extended to house the additional computing resources required by the upgraded DAQ, and it will include the space currently occupied by the CMS control room. The Phase-2 OLC will house (among the usual site management IT infrastructure) the network and compute nodes needed to assemble the back-end data into coherent physics events, the high level trigger, as well as a cluster file system providing buffer storage for the physics data in case of interruptions of the CMS-to-CERN transfers.
The refurbishment of the CMS online data centre will be carried out in collaboration with the EN-EL and EN/CV groups for the electrical and cooling infrastructure, and with the IT department for the general networking.
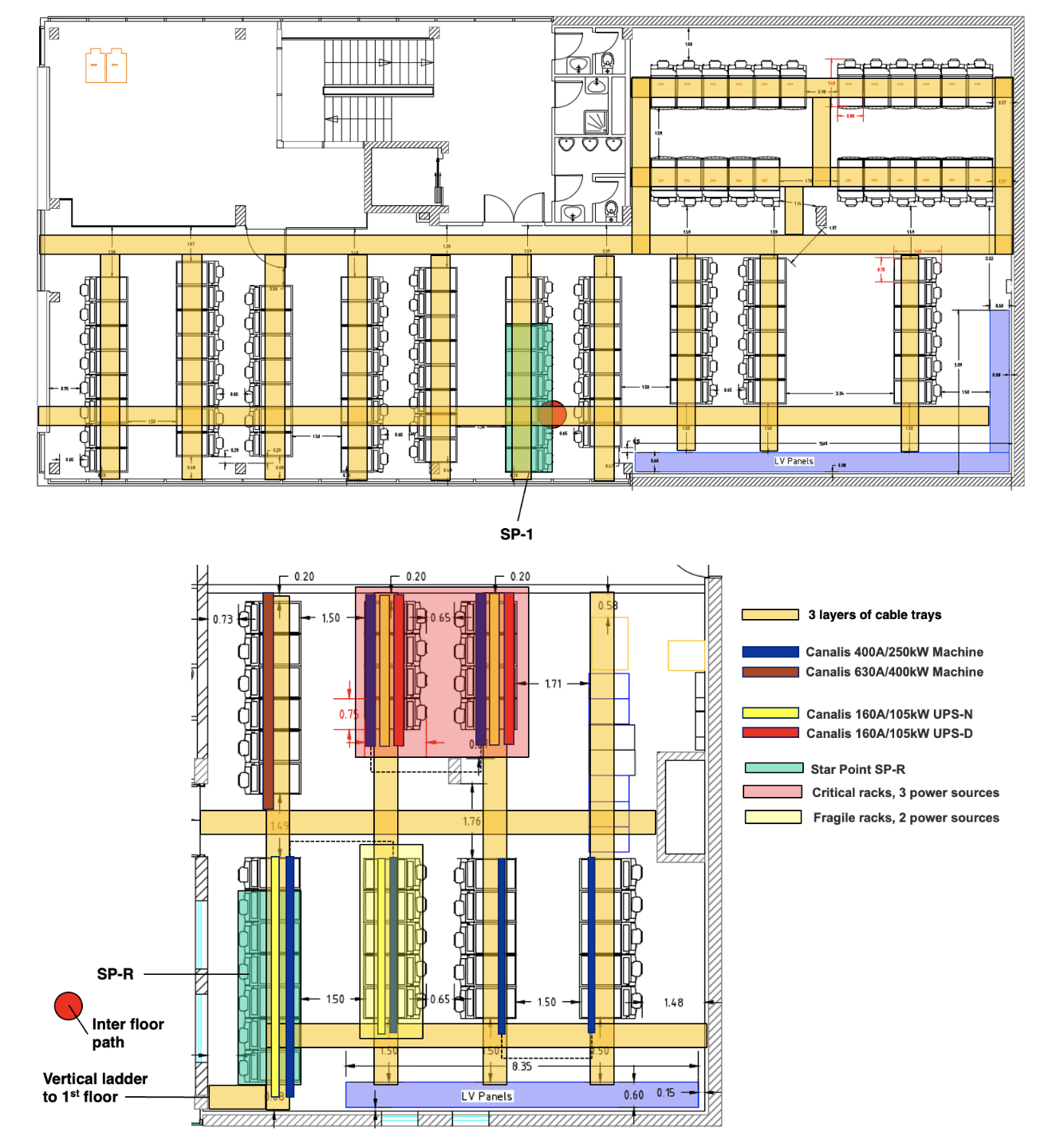
Figure 4: The CMS OnLine Computing centre (OLC) will be extended in Phase-2 to include the area currently occupied by the control room (bottom of the figure). The control room will be relocated in a new building. The additional space will be used to house additional computing for the DAQ event builder and the HLT farm, as well as redundant IT services for the experiment.
The CMS High Level Trigger from Run-3 to Run-4
A key aspect of the CMS Trigger and DAQ design is that the HLT selection algorithms are executed within the exact same reconstruction framework as used offline. This early design choice has proven extremely important to efficiently exploit the physics potential of the experiment. A full-fledged reconstruction framework provides flexibility in implementing the selection algorithms, enables the re-use of a large fraction of the reconstruction code developed for offline reconstruction, and makes it possible to swiftly migrate novel offline algorithms and selection strategies to the online environment - and vice versa.
With the beginning of Run-3, CMS has pushed the technology used in the HLT computing farm to a new level, with the deployment of GPU-equipped nodes. This follows the path pioneered by ALICE in Run-1 and adopted also by LHCb in Run-3 - and makes the extra step of seamlessly running the physics reconstruction on CPUs and GPUs within a single application, sharing the same code and data processing framework.
The role of the HLT is to start with the events accepted by the Level-1 Trigger (L1T) at a rate of 100 kHz, reconstruct and analyse them, and select a few kHz of events that maximise the physics potential of the experiment.
During LS2, the old HLT farm has been decommissioned and replaced with 200 new machines. Each of them is equipped with two AMD “Milan” EPYC 7763 CPUs with a total of 256 logical cores, 256 GB of system memory, and two NVIDIA “Turing” T4 GPUs. The efficient use of such large machines requires multithreaded applications, where a single program uses many CPU cores to analyse multiple events at the same time.
CMS introduced the use of multithreading at HLT at the beginning of Run-2 to reduce the amount of memory required, replacing the previous approach based on multi-processes. By 2016, CMS was running only multithreaded applications at the HLT, analysing four concurrent events per job. Thanks to the advancements in the CMS software framework that can leverage more of the underlying parallelism, in Run-3 the HLT is running jobs with 32 threads, each processing 24 concurrent events, without any significant loss in performance. This is a critical achievement that simplifies sharing GPUs across multiple applications, reduces the amount of required system and GPU memory alike, and enables the deployment of more GPU-based reconstruction algorithms.
In 2022 the CMS HLT has been running four groups of algorithms on GPUs: the local reconstruction of the electromagnetic and hadronic calorimeters, the local reconstruction of the pixel tracker, and the reconstruction of tracks and vertices based on the pixel information. The physics performance has been improved compared to Run-2 thanks to the adoption of more accurate track reconstruction algorithms, made possible by the additional processing power provided by the GPUs.
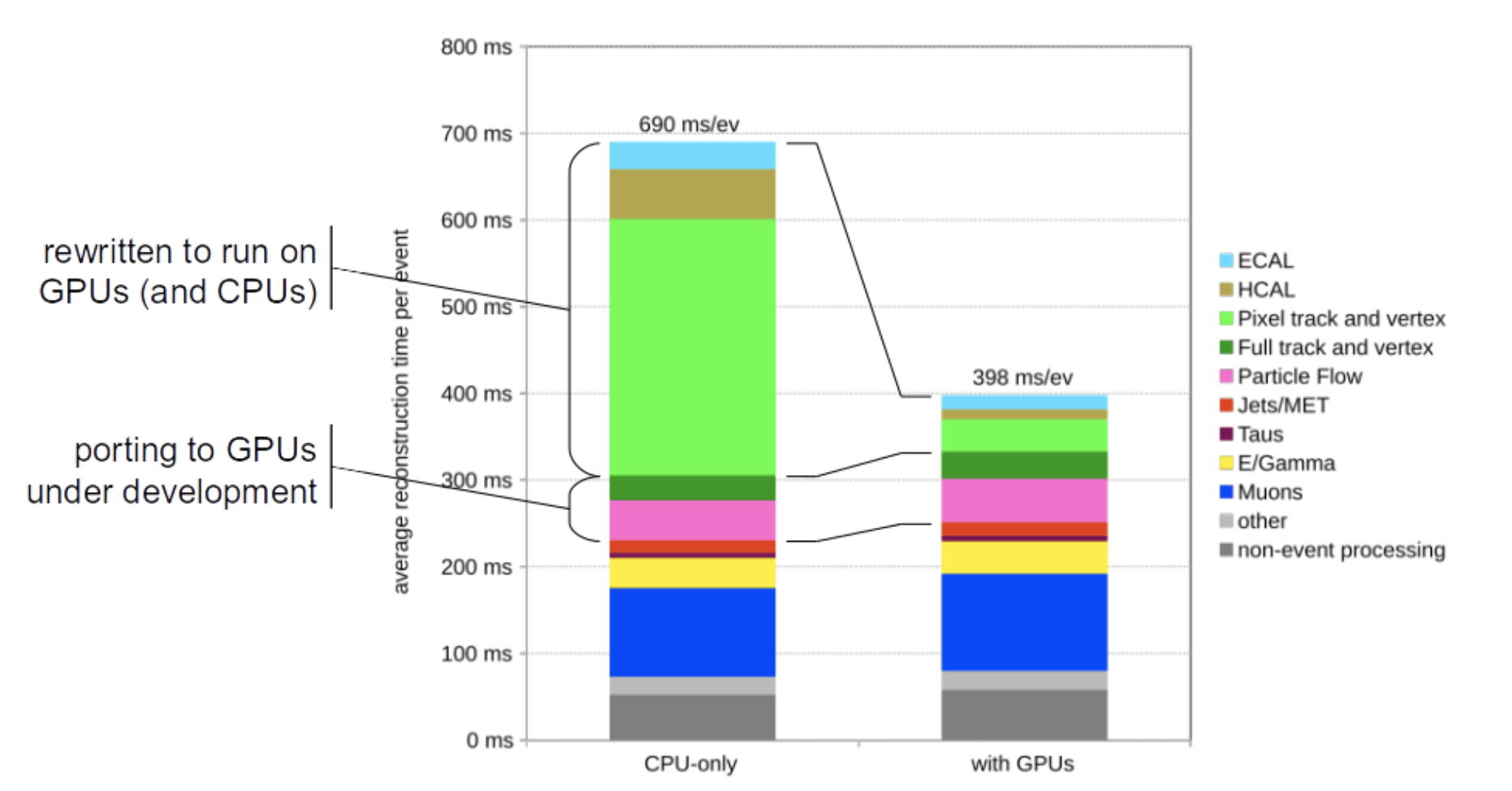
Figure 5: The use of GPUs to offload the calorimeters local reconstruction and the track reconstruction based on the inner tracker information reduces the processing time by over 40%.
Offloading these algorithms to GPUs CMS reduced the HLT reconstruction time by over 40%, with a 70% increase in event processing throughput, meeting and exceeding the performance required to process events at a rate of 100 kHz. With respect to a traditional computer farm this achieved 20% better performance for the same initial cost, and 50% better performance per kilowatt - a welcome saving in today’s energy-constrained scenario.
Having established these results as a solid baseline CMS is now working to expand the use of GPUs to more reconstruction algorithms and to develop more flexible technical solutions, both for the ongoing Run-3 and for the future Phase-2 upgrade.
The CMS Phase-2 reconstruction is being designed with the use of GPUs in mind: the 2D and 3D clustering algorithms for the High Granularity Calorimeter (HGCAL) are already running on CPUs and GPUs, and achieve a significant speedup on the latter. At the same time, more of the Run-3 reconstruction is being redesigned to run on GPUs: the full vertex reconstruction, the particle flow algorithm, with the latest effort to run the electron seeding on GPUs.
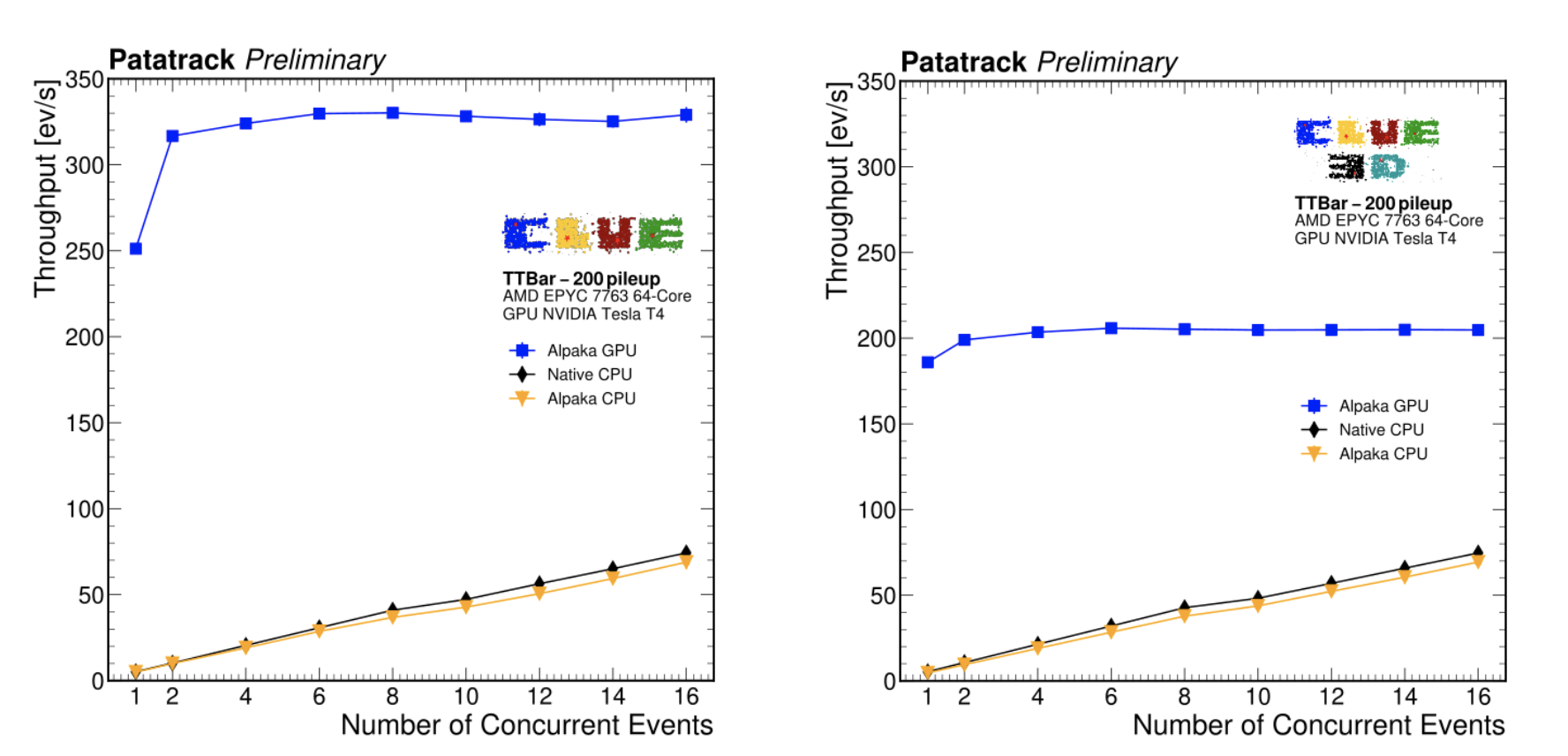
Figure 6: Processing throughput of the 2D (CLUE) and 3D (CLUE3D) clustering algorithms for the CMS High Granularity Calorimeter in simulated events with 200 pileup interactions, running on CPUs (black and yellow lines) and GPUs (blue lines) on a node of the HLT farm.
Today the CMS reconstruction is written using the CUDA platform to run on the NVIDIA GPUs present in each node. To avoid vendor lock-in, ease the adoption of different architectures, and minimise the development and validation work, CMS has adopted a performance portability solution: the alpaka library developed by the CASUS institute at HZDR. And, to make use of GPUs in different nodes, a transparent support for remote offload over high-speed networks is being developed. The development of the framework and application modules running on heterogeneous platforms was done by the CMS collaboration at large, including essential contributions by the EP-CMG and EP-CMD groups.
The result obtained during the first year of Run-3 shows that CMS is putting the new HLT nodes and the GPU reconstruction to very good use, and is already close to the target set for Run-4, of offloading to GPUs at least 50% of the online reconstruction. With the ongoing work on the use of different accelerator architectures and the redesign of the physics reconstruction to leverage them, the final goal of offloading more than 80% of the reconstruction does not seem so far away!
Further reading:
The Phase-2 upgrade of the CMS data acquisition and High Level Trigger - Technical design report: https://cds.cern.ch/record/2759072/files/CMS-TDR-022.pdf
CMS Phase-2 data acquisition, clock distribution, and timing: prototyping result and perspectives: https://doi.org/10.1088/1748-0221/17/05/C05003
The Phase-2 Upgrade of the CMS Data Acquisition: https://www.epj-conferences.org/articles/epjconf/abs/2021/05/epjconf_chep2021_04023/epjconf_chep2021_04023.html
The latest developments on the use of GPUs at HLT during Run-3 and targeting Phase-2 were presented last October at the ACAT 2022 conference, in Bari. The most relevant contributions among many other are:
- Commissioning CMS online reconstruction with GPUs: https://indico.cern.ch/event/1106990/contributions/4991283/;
- Adoption of the alpaka performance portability library in the CMS software: https://indico.cern.ch/event/1106990/contributions/4991273/;
- Performance study of the CLUE algorithm with the alpaka library: https://indico.cern.ch/event/1106990/contributions/4998189/.