![]()
ATLAS scales up AI for jet physics and reveals flavour-tagging scaling laws

High Energy Physics (HEP) and Machine Learning (ML/AI) are uniquely aligned: The data recorded by particle physics experiments are so rich, heterogeneous and complicated that scientists crucially depend on advanced pattern recognition in order to extract physics results. It’s for this reason that HEP has historically been one of the earliest adopters of ML in the sciences. With the advent of modern deep learning in 2012, this close connection has been rejuvenated and has fueled an intense effort to exploit neural networks to improve and accelerate particle physics workflows across the board.
In the wider ML/AI domain, especially in the fields of computer vision and language models, a major underlying mechanism driving accelerated progress has been the exploitation of scale. Modern AI is trained on internet-scale data, and state-of-the-art models reach trillions of parameters. In comparison, the AI models used in production at LHC experiments, with millions of parameters, are still small. This raises the question: Can HEP also benefit from scaling up?
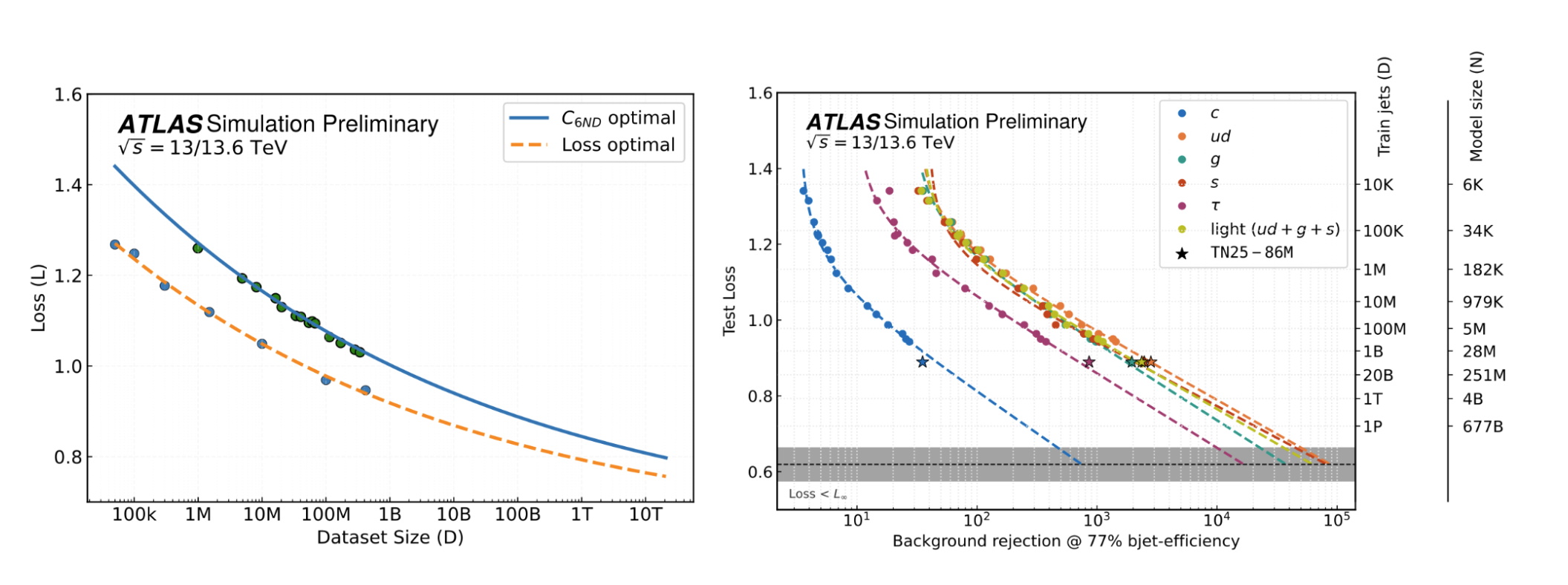
Scaling behaviour of transformer-based jet flavour taggers in ATLAS. Left: Test loss as a function of dataset size, illustrating the expected improvement along compute-optimal and loss-optimal scaling trajectories. Right: Corresponding gains in physics performance, shown as background rejection at fixed b-jet efficiency (77%) for different jet flavours, with increasing model and dataset size. The results demonstrate that scaling both data and model capacity leads to systematic and predictable improvements in flavour-tagging performance, with no sign of saturation at current scales.
The answer is not a foregone conclusion. The detectors we build come with an intrinsic resolution limit due to the sensor granularity alone. No amount of advanced data analysis can overcome it. If the current techniques we deploy at LHC experiments bring us already close to this intrinsic resolution limit, we would face diminishing returns in scaling to larger datasets and more complex models.
A new study by the ATLAS Experiment gives a clear answer. The study, aimed to understand the scaling behaviour of one of the major AI applications in particle physics - jet flavour tagging, which, among many other applications, is crucial for understanding the Higgs boson (see ATLAS Collaboration, Nature Communications, 2026). And indeed, by adding more data, the pattern recognition performance continues to improve significantly, a clear sign that we are far from that ultimate physics performance limit!
For this study, ATLAS has pushed the frontier in data scale to an unprecedented level. While the current generation of production-grade algorithms is trained on approximately 300 million jets, this new study created a new dataset with up to 7.7 billion(!) jets - an almost 25-fold increase and possibly the largest jet dataset used for AI model training to date.
The results show that not only does performance improve with more data, but the improvement appears similarly regular as it is for language models. The study derives empirical “Scaling Laws” that, for the first time allow us to make quantitative predictions about what physics performance can be reached for any given data and compute budget. Should these scaling laws continue to hold, we would expect that even at a scale of 100 billion or even a trillion jets, the performance would not yet saturate. Training models at that scale would indeed require multi-billion parameter models similar to industry, which motivates a serious investigation into how such large-scale AI models can be trained within the HEP community in the near future and how to further scale up the required datasets.
Finally, as we enter a new scaling era of AI in particle physics, new questions come into view: First, the scaling laws were derived on datasets of simulated jets and represent only a first estimate of physics performance. Will their predictions hold after the algorithms have undergone the careful calibration required for production-grade deployment? Second, can we teach these large-scale models to do more? Ideally, models trained with such enormous resources should perform not one but many tasks that go far beyond object tagging. Mirroring so-called “foundation models” in computer vision and language, research into such “Large Physics Models” is underway and may yield an answer in the years to come.
Further reading
- ATLAS Collaboration, Transforming jet flavour tagging at ATLAS, Nature Communications (2026)
- ATLAS Collaboration, Carpe Datum: Scaling behavior of transformers for heavy hadron flavor identification, ATL-SOFT-PUB-2026-002