![]()
Can AI help us to find tracks?
Data science (DS) and machine learning (ML) are amongst the fastest growing sectors in science and technology, not at least due to their strong rooting in industrial and commercial applications. Global players such as Google, Facebook and Amazon have surpassed HEP in both, computing complexity and data volume. Recent advances in machine learning and artificial intelligence have made it more and more attractive to try to apply such algorithms in event reconstruction. While data analyses have been using machine learning techniques since a rather long time (and indeed very successfully), the application within the event reconstruction is less widespread, although there are certainly areas which could greatly benefit from such inclusion. One particular question is whether ML and DS can aid the pattern recognition in the high particle multiplicity environment of the HL-LHC of beyond, with the aim of lowering the computing impact of the future experiments. In particularly the track reconstruction is - due to its combinatorial character - a heavily CPU intensive task.
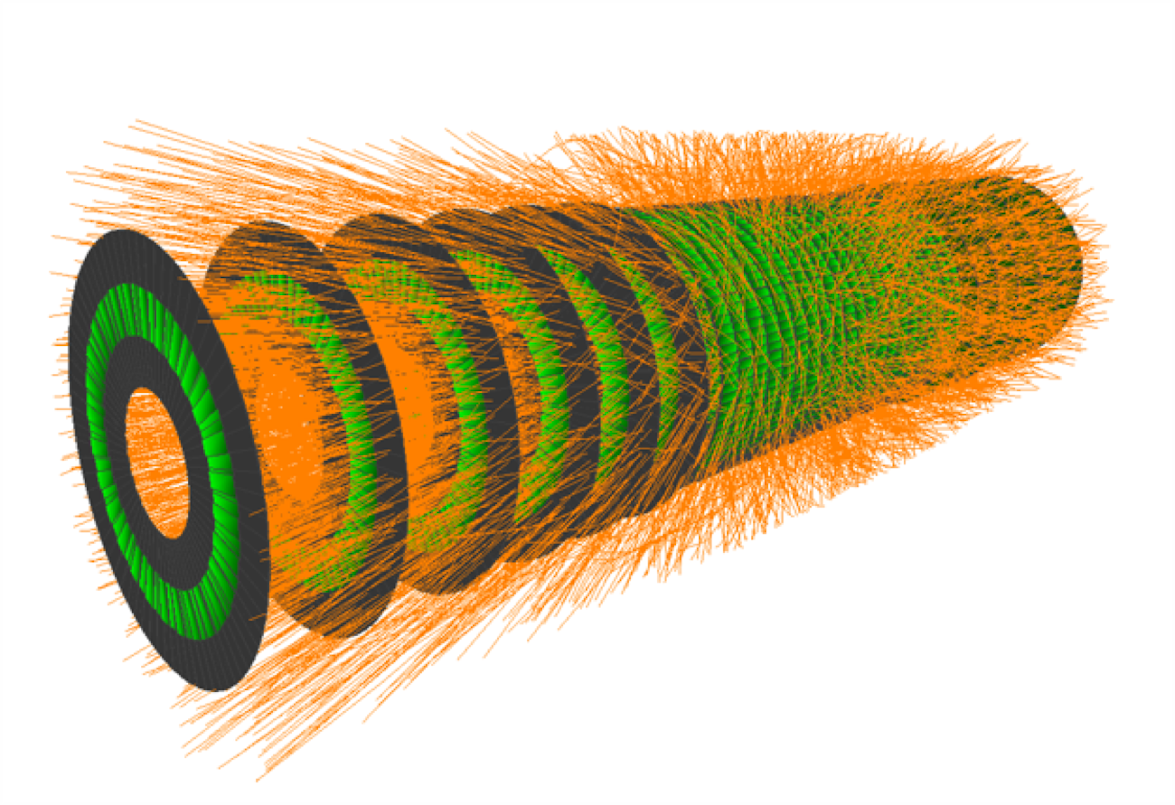
Figure 1: A detailed view of the short strip detector of the Tracking Machine Learning challenge with a simulated event with 200 pile-up interactions.
Based on the experience and the broad resonance of the Higgs Machine Learning Challenge organised in 2018, the Tracking Machine Challenge (TML) was launched in April, designed to run in two phases that focus first on accuracy (Phase 1) and then execution speed (Phase 2). The idea of such a challenge is as simple as it is compelling: a large-scale dataset is provided to the public, together with the template truth solution and a prescription of the score (or inverse cost) function. In short words, the score function attributes a positive score for each correctly assigned measurement, while penalizes wrongly assigned ones. The dataset for the challenge resembles conditions that are expected at the HL-LHC: on average 200 simulated instantaneous proton-proton collisions are overlaid with one signal event (top quark pair production), a perfect score of 1 hereby indicates that all measurements of reconstructable particles (i.e. more than four measurements are created by this particle) stemming from these collisions are correctly assigned.
The competitors are then left to find their best solution, which they have to provide for a smaller test dataset where the ground truth is removed. By uploading the solution to the challenge platform, each submission is ranked by using the truth information on the platform server. Prize money of 25 000 dollars for the winning teams and special jury prices were provided by sponsors of the TML challenge.

Figure 2: The evolution of score from contestants of Phase 1 during the submission phase. The starting score of 0.2 is given by the starter kit solution that implemented a simple solution built on DBScan.
In total, 656 teams from within and from outside the HEP community submitted nearly 6000 solution attempts during the submission period of Phase 1, which was hosted on the kaggle platform.
The lessons from Phase 1
The final leaderboard of Phase 1 was a mix of classical pattern recognition and ML based/inspired solutions, with both approaches reaching scores of up to 0.92. The winner,
Johan Sokrates Wind (albeit named top quarks in the competition), is from outside the HEP community. He performed a mixture of classical pairing/seeding followed by ML assisted pruning of the candidate and executed the task in roughly 15 seconds per event, comparable to what current HL-LHC reconstruction might take. The runner up, Pei-Lien Chou, on the other hand had a fully trained model based on deep learning, in particular the relationship of pairs of hits. The training model consisted of five hidden layers of several thousand neutrons in order to accommodate the dataset and the execution time of finding a solution relied on pair building was consequently orders of magnitudes slower. All, in all, an interesting mix of classical and ML based solutions were presented and are currently being analysed.
The astonishing numbers of Phase 2
For Phase 2, the dataset has only been slightly changed: a few feature in the data set have been correct, such as a too narrow beamspot simulation in Phase 1. The reconstruction target was changed to include only particles emerging from the beam-beam interaction, secondary particles were omitted in the scoring function.
The detector setup was kept identical, although the scoring function and the mechanism was modified: as the figure of merit in Phase 2 included the throughput time as a one of the scoring parameters. This required the development of a special platform setup, which was done in cooperation with the platform host of the Phase 2, codalab [ref]. The accuracy based score of Phase-1 was augmented with a timing scoring, which was measured at submission in a controlled way: the submitters had to submit their (compiled or non-compiled) software with a dedicated API such that the in-memory dataset for the scoring events could be pushed through and both, the accuracy and speed measured at the same time in a controlled environment (2 cores with each 2 Gb memory were dedicated for each submission process). Evidently, due to the more restrictive submission pattern, but also caused by the time limit available for a submission to be successful, the number of teams submitting to Phase 2 had decreased significantly.
Phase-2 closed on March 13, 2019, with truly remarkable results. The leading submission achieves a better than a Hz throughput time for primary reconstruction of a typical HL-LHC event, while keeping an accuracy score of roughly 0.94, followed up by a very similar solution that executes only slightly slower.
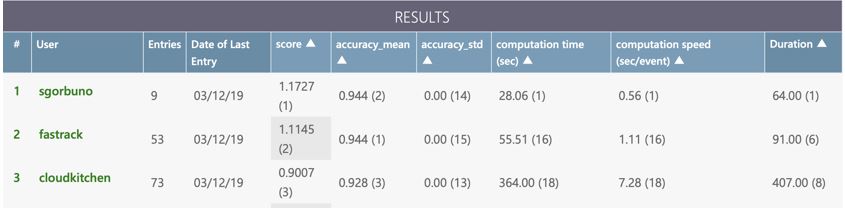
Figure 3: Final development result table for the Phase 2 (throughput phase) of the Tracking Machine learning challenge.
Where to go from here
The solution from Phase 1 and 2 are currently being analysed in detail, and some of them will find their ways into the experiments’ software stacks. In the meantime, the TrackML dataset is being consolidated, the fast simulation augmented with a smaller scale full simulation for cross comparison, and a reference detector and dataset prepared to be published on the CERN OpenData portal. Similarly like the NIMST data set for letter recognition, this will allow to perform future algorithmic development & performance evaluation.
Are we in the era where machines learn how to do the event reconstruction for HEP? The honest answer needs to be: not yet. But times are changing.
Related resources
[1] https://www.kaggle.com/c/higgs-boson
[2] https://sites.google.com/site/trackmlparticle/home
[3] https://www.kaggle.com/c/trackml-particle-identification
[4] https://competitions.codalab.org/competitions/20112
[7] http://yann.lecun.com/exdb/mnist/