![]()
Upgrading the LHCb trigger system

The LHCb experiment is undergoing a significant upgrade during LS2 in order to allow it to run at a five times higher instantaneous luminosity in LHC Run 3. In order to deal with the corresponding increase in pileup per bunch crossing, most of the LHCb subdetectors are being upgraded to improve their granularity, including a complete replacement of the tracking system, the installation of a new pixel vertex detector and a complete overhaul of the fron-end electronics to allow to read out data at 40 MHz rate. The upgrade of the LHCb trigger is one of the greatest data challenges attempted in HEP. At the heart of this upgrade lie the LHCb’s DAQ and trigger system, which will allow the entire detector to be read out at 40 MHz and reconstructed in real time in software using commodity processors for the first time. Reading out and processing 40 Tb/s in real time, the upgraded LHCb DAQ has a comparable readout rate as the full ATLAS and CMS HL-LHC detectors. Although LHCb’s software was incrementally optimized throughout Run 1 and 2, it was clear that such an incremental approach would not scale towards Run 3. For this reason the collaboration has since 2015 engaged in a full rewrite of its reconstruction and selection software to enable it to take advantage of modern highly parallel processing architectures.
A real-time detector reconstruction is necessary because LHCb is optimized to study, with high precision, relatively light but abundantly produced particles like beauty and charm hadrons, whose signal rates in the LHCb detector will exceed 1 MHz in the upgrade/next run(s) of the LHC. This abundance of signal has two consequences. First of all, because the signal particles are light, it is not enough to look at calorimeter or muon information in the first trigger level. Instead, LHCb must reconstruct tracks and combine momentum and decay vertex information to select the most interesting 0.5–1 MHz of events for further processing. Secondly, LHCb must then perform a full offline reconstruction of these selected events in the second trigger stage, using a real-time alignment and calibration of the detector. This in turn allows LHCb to select signals with high purity and discard in real time most of the detector information not associated to these signals; a process called “real-time analysis” which was first deployed at the LHCb experiment as a proof-of-concept in Run 2.
Compared to Run 2, the upgrade software trigger will have to cope with a five times higher instantaneous luminosity and a thirty times higher read-out rate. It became clear early on in the design process that using the available computing resources in the same fashion as in Run 2 will not scale with the same factors. Modern computing architectures get their processing power from an increased amount of compute cores where several threads process the data in parallel (thread-level parallelism), and an increased amount of instruction-level parallelism where the same instruction operates on multiple data simultaneously (Single Instruction, Multiple Data). It was therefore necessary to redesign LHCb’s software framework and scalar algorithms to efficiently utilise such highly parallel architectures.
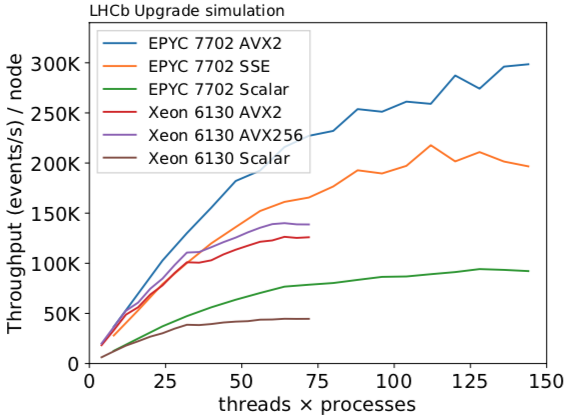
A common problem with highly parallel computing is the interference of threads. This can manifest itself in two threads blocking each other as they need the same resources, or in one thread undesirably changing the state of another. To avoid these problems LHCb has implemented a simple but effective model: every algorithm must explicitly define all its inputs and outputs, and the algorithm must not have any “state” or memory of whether it was executed before. The requirement that algorithms are stateless makes sure that running the same algorithm on multiple events in parallel does not lead to interference. While thread-level parallelism is handled by the underlying software framework (“Gaudi”), exploiting instruction-level parallelism is specific to individual algorithms and has to be done manually by the developer to be most effective. Existing algorithms are often not suited to this process of vectorization. Because the optimal approach can depend on the specific computing architecture, it is interesting to perform R&D in parallel for different architectures. Putting these concepts together in the reconstruction software has led to a near-linear scaling with the number of physical cores, shown in Figure 1, which is the theoretical best case. This demonstrates that, unlike the Run 2 code, LHCb’s upgrade software can efficiently exploit modern x86 computing architectures.
Alongside optimizing its x86 software, LHCb has since around 2013 also been exploring the highly parallel architecture of graphics processing units (GPUs). The key concepts of multi-threaded many-core x86 programming apply similarly to the GPU architecture, which enabled cross-platform development. In particular, algorithms are designed by data flow in the two cases and the Structure of Arrays (SoA) data layout is ideal whether for access by x86 vector instructions or by GPUs threads. Furthermore, the parallelization levels within one event were explored concurrently for vectorized x86 and GPU algorithms. For example, the reconstruction of tracks in the vertex detector benefited greatly from an exchange of improvements found in the optimal GPU and CPU implementations []. Compared to the x86 architecture, GPUs have a limited amount of memory available (on the order of tens of GB), however because the raw event size at LHCb is about 100 kB this still allows thousands of events to be processed in parallel and does not limit the system. Similarly, the I/O performance of the 3rd generation PCIe bus (16 GB/s) used by current state-of-the-art GPUs was already sufficient to satisfy LHCb’s Run 3 requirements. The 4th generation cards coming onto the market now provide significant margin on top of what is needed.
The main tasks of the upgrade first-level trigger are charged particle reconstruction in LHCb’s three tracking detectors, muon identification, primary and secondary vertex reconstruction and inclusive selections which reduce the event rate by a factor of between 30 and 60. Because the first level trigger consists of a relatively small number of algorithms that are inherently highly parallelizable, LHCb was able to implement complete and viable first-level triggers on both x86 and GPU architectures. In both cases a few hundred modern CPU servers or consumer GPU cards are sufficient to process the incoming 40 Tb/s data stream and reduce the data rate for subsequent alignment, calibration and processing by the full LHCb reconstruction. Figure 2 shows the throughput for the first trigger stage on various GPU models as a function of their theoretical 32-bit FLOPs performance. Analogously to the earlier CPU plot, this linear behaviour shows an optimal exploitation of the underlying architecture.

Advancing the software while at the same time teaching people these changes and integrating new developers into the team is a challenging process. LHCb has invested a great deal of effort into this since Run 1, with a gradually increased focus on providing documentation, as well as organising dedicated training sessions called “Starterkits” for newcomers. In addition, LHCb organizes several times per year so-called hackathons. People of all levels of experience, from total beginners to the core developers, get together to work on the software. Here we use the facilities provided by the IdeaSquare at CERN to create a collaborative and welcoming environment. Discussions in the Red Bus or in the kitchen while having lunch together are always fruitful, and the physical distance of the IdeaSquare from the main Meyrin site protects participants from distractions. The hackathons successfully serve two purposes. First, people brainstorm over solutions to difficult problems and new developments are seeded by these ideas. Second, newcomers learn to work with the software and profit from the direct support of more advanced collaborators. Often the age plays no role, PhD students help post-docs and vice versa.
The successful rewrite of LHCb’s software enables our real-time analysis model introduced in Run 2 to continue into the upgrade. In this model, publication-quality analysis is performed in the trigger itself. For the majority of LHCb’s physics programme this means [] fully selecting the signal candidate in real-time, and permanently throwing away detector information not associated with this candidate. Such exclusive trigger selections bring inherent improvements in signal efficiency in comparison to relying on inclusive triggers, because a greater number of signal candidates can be recorded for the same available storage space. However, capturing the full breadth of the broad LHCb physics programme means a large number of selections must be implemented. In Run 2, the final trigger stage defined around 600 individual selections. In Run 3, a comprehensive exploitation of the real-time analysis model will result in around 2000 selections running in the trigger simultaneously. These lines must be written by physics analysts, who do not necessarily know the details of the trigger but understand best the tradeoffs in signal efficiency and systematics involved in trigger selections.
Writing such selections involves piecing together individual algorithms into a complete trigger configuration. The selected/designed framework used to define this configuration is just as critical to the trigger as the high-performance reconstruction algorithms. It ensures that configurations are reproducible, well tested, that selections do not interfere with each other, and that physics analysts can intuitively understand what the trigger does. Providing an intuitive configuration framework is key in helping physicists go from ideas to implementation in as little time as possible. For this reason, a significant and coordinated effort has gone into a complete redesign of this framework for Run 3. Inspired by the earlier Starterkits, the framework has been documented from the ground up, providing even the least experienced LHCb members with an accessible entrance point. Physics analysis working groups have responded positively and started the effort of writing Run 3 trigger selections in earnest, with over 100 lines already in place. This teamwork will be crucial to ensure the smoothest possible commissioning and startup during Run 3.
The rewrite of LHCb’s software, which has gone hand-in-hand with the modernization of its development model, has involved more than 100 physicists and computer scientists over a period of five years. And these efforts are paying off: not only has the reconstruction become many factors faster and uses factors less memory, greatly reducing the cost of the Run 3 processing, but the collaboration even has the luxury of choosing between a first-level trigger implemented on CPUs or GPUs. This effort will also serve as an excellent template for the even bigger challenges of the future LHCb upgrades, which have the ambition of processing over 400 Tb/s of detector in real-time. In this context, the lessons learned by LHCb in cross-architecture development will be particularly relevant to leave the collaboration maximum flexibility to react to future and often unpredictable trends in commercial processing hardware.