![]()
Data Quality Monitoring: An important step towards new physics
Data Quality Monitoring (DQM) is an important aspect of every high-energy physics experiment. In the era of LHC, when the detectors are extremely sophisticated devices, an online feedback on the quality of the data recorded is needed to avoid taking low quality data and to guarantee a good baseline for offline analysis. This is becoming essential again following the restart of the LHC and the successful proton-proton collisions recorded in the first week of June. The LHC experiments are now taking data at the unprecedented energy of 13 TeV, almost double the collision energy of its first run. This will mark the start of Run 2 at the LHC, opening the way to new discoveries.
An important step toward to search for new physics is to be able to get good data sets from the collisions; this is why all the four major LHC experiments upgraded some of their subdetectors and subsystems during LS1, while the higher amount of data pose an extra challenge. This all makes it all the more important to design algorithms and special software to control the quality of the data recorded by each experiment. We asked the Data Quality Monitoring teams of the four experiments to present the tools they are using and how the DQM is organized to fit the specifications of each detector.
ATLAS
The machinery of the LHC and the ATLAS experiment were decades in the making and the luminosity for physics analysis is being delivered over periods of months and years, but the ATLAS collaboration is keeping track of the quality of its data minute-by-minute. The monitoring in real time, also referred to as online, is designed to catch and diagnose problems quickly in order to minimize data losses. The monitoring that follows data storage, also referred to as offline, is designed to categorize the data as usable or not according to the stringent needs of various physics analyses.
How do we keep track of the millions of readout channels and the changing detector conditions by the minute? An important requirement is robust book-keeping that is a partnership between the ATLAS data acquisition system and the databases that interface with it. Fine-grained information about voltages, hot towers, dead channels, temperatures, magnetic field strengths and many other variables capture the current detector status. This fundamental information is monitored using automated checks designed to spot irregularities and signs of problems.
Each detector that makes up ATLAS has its own monitoring to catch problems in real time and give an overview of performance. We also monitor reconstructed objects: electrons, muons, jets, taus, missing transverse energy and other quantities. These objects are sensitive to detector performance and often combine information from multiple sub-detectors, giving an overview of the quality of the data from the physics analysis perspective. The detector-level and reconstructed object monitoring occur both on- and offline and an attempt is made to keep the monitored quantities similar between these two categories so that cross-checks are possible.

Diagram showing the structure and workflow of the ATLAS Data Quality Monitoring System.
The 48 hours that follow data-taking are used to perform an initial processing of a subset of the data to extract calibration and alignment information. In parallel, a first assessment of the data quality offline is performed. If all goes well, the data is reprocessed using this up-to-date information. The final data quality assessment is then performed using a series of flags to categorize the data as good or not with the granularity of a one-minute-long luminosity block. When requested, the data quality group hands the collaboration a list of these luminosity blocks that are good for physics analysis.
The system only works thanks to the constant and expert attention of many people who understand what the monitored quantities ought to look like throughout the various stages of data taking and offline processing. This team provides a crucial service for the collaboration, not only determining the goodness of the data but also helping to ensure that the fraction of good data remains high. The beginning of Run 2, when we are commissioning new sub-detectors and dealing with new running conditions, is particularly exciting as we work to maximize the fraction of ATLAS data that can be used for physics.
CMS
As is the case for all the experiments, CMS has developed its own DQM system that provides the central foundation of all data certification and validation within the experiment. The DQM workflows are tailored to each environment in which they live, as shown in Fig. 1.

Usage of the DQM framework in the CMS experiment
For real-time (online) monitoring, the data are sampled to perform a live monitoring of each detector’s status during data taking. This gives the online crew and shift leader the possibility to identify problems with extremely low latency, minimizing the amount of data that would otherwise be unsuitable for physics analysis. In the offline environment, the system is used to review the results of the final data reconstruction on a run-by-run basis, serving as the basis for certified data used across the CMS collaboration in all physics analyses. In addition, the DQM framework is an integral part of the prompt calibration loop. This is a specialized workflow run before the data are reconstructed to compute and validate the most up-to-date set of conditions and calibrations subsequently used during the prompt reconstruction. In release validation, a central workflow run biweekly, the DQM system is used to assess the goodness of updates to reconstruction algorithms and high-level physics objects definitions that are regularly integrated in the CMS software release framework (CMSSW). Similarly, the DQM framework is employed during the early stages of Monte Carlo production to monitor the quality of samples that are ultimately used in data analyses for publication.
For all scenarios, a common set of tools was developed, designed to be flexible and robust to not only maintain a high degree of stability, but also to allow flexibility for multiple use-cases in an ever-evolving framework. These core components are shown in Fig. 2 and comprise of the following: a unique block of shared memory that internally holds all DQM information (DQMStore), a wrapper class for ROOT histograms (MonitorElements) needed to hold quality reporting information and links to reference histograms, the quality tests package to configure and perform certification tests on individual histograms for automated monitoring and certification, a software layer that links DQMStore directly into CMSSW, and a network layer responsible for connecting many DQM applications from many machines to a centralized web application (DQMGUI). The DQMGUI collects and aggregates all received data, and provides a visualization platform of all delivered histograms for the CMS collaboration worldwide.

Core components of the DQM framework.
During the long shutdown, a number of fundamental changes were made to the environment surrounding the DQM framework to which it had to adapt. For the online environment, the data acquisition system moved to a completely file-based system, using shared file systems to deliver data and indicate state and run transitions of the systems. In the offline environment, the entire monitoring framework was updated in sync with the transition of CMSSW to run in a multithreaded environment. In both cases, the flexibility of the DQM system allowed for a seamless transition to Run2 data-taking with these fundamental changes in place, providing prompt feedback and certification of CMS data to the entire collaboration for the beginning of another exciting era for CERN and the LHC.
ALICE
ALICE, the dedicated heavy-ion experiment, has to deal with large amount of data due to the different nature of the colliding objects. Particularly the higher multiplicities produce an enormous amount of data that have to be quickly controlled and monitored to ensure a smooth data-taking and the maximum performance of each detector. These were two of the particular challenges faced while developing a DQM for ALICE.
To control the quality recorded in one of its subdetectors, ALICE is using a software called AMORE (Automatic MOnitoRing Environment) that provided fast feedback in order to help shifters and experts to identify potential issues in advance. DQM involves the online gathering of data, their analysis by user-defined algorithms and the storage and visualization of the produced monitoring information.

Image Credit: Barthelemy von Haller@CERN
AMORE is based on the widely-used data analysis framework ROOT and uses the DATE (Data Acquisition and Test Environment) monitoring library. Automatic DQM requires a many-to-many client-server paradigm in order to serve the several monitoring needs and make possible such advanced functionalities as fast reconstruction or correlation between different detectors. A large number of processes, named agents, execute detector-specific decoding and analysis on raw data samples and publish their results in a pool. Clients can then connect to the pool and visualize the monitoring results through a dedicated user interface. The pool is implemented as a database.
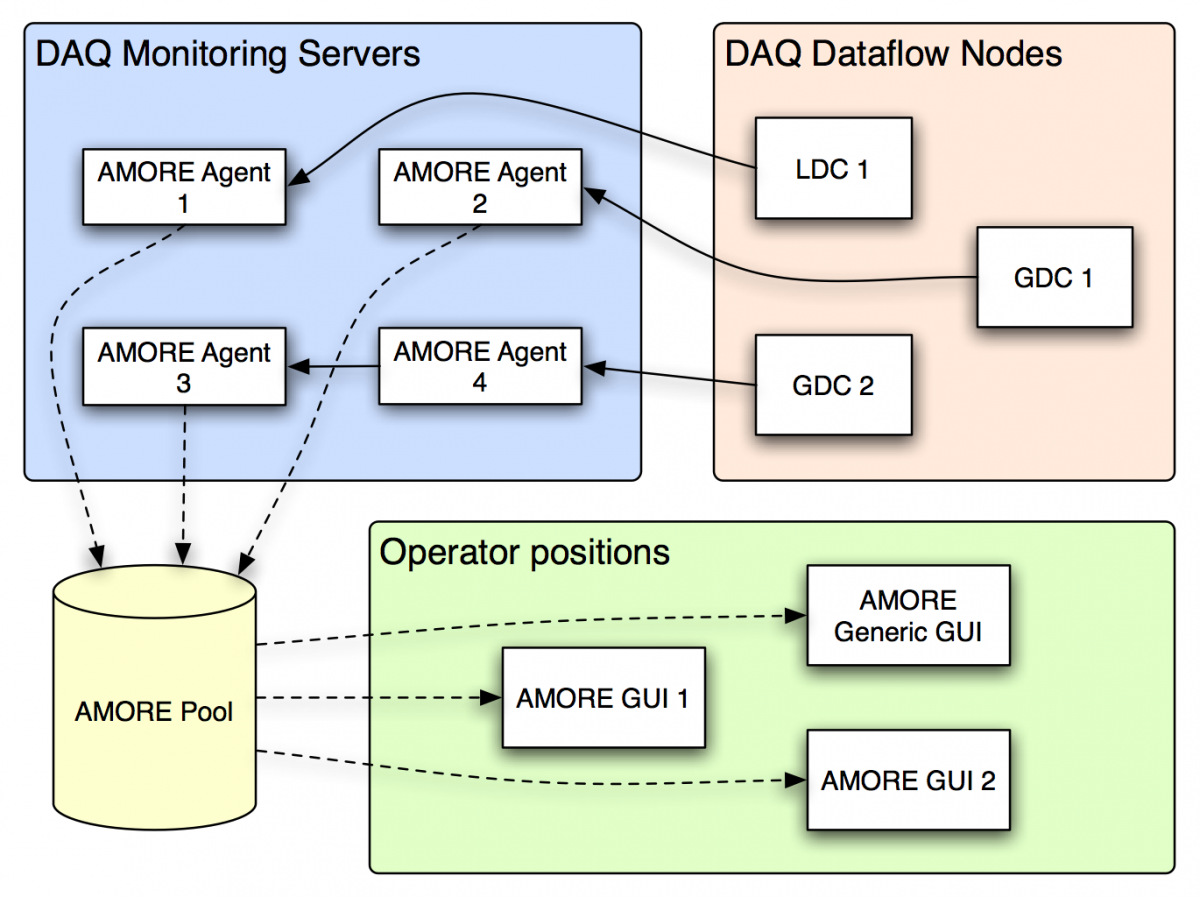
The AMORE workflow

Plot generated by one of the DAQ AMORE modules to monitor the data size of the detectors over time (Image Credit: Barthelemy von Haller@CERN).
The open-source MySQL system was chosen as it proved to be reliable, performant and light-weight. The database contains a table with a list of all the agents, specifying on which machine they are allowed to run and to which detector they belong. Another table contains configuration files, that are optional and allow each detector to define, by instance, different configurations corresponding to different run types. Finally, a data table is created for each agent where the published objects are stored. The subscriber part of the users’ modules mainly consists of a Graphical User Interface (GUI) capable of handling the objects produced by the publishing part. As the basic needs of most of the detectors teams were very similar, a generic GUI has been developed in order to avoid code duplication and ease users’ lives.
The GUI can be used to browse and visualize any object of any running agent. An access through the web, thanks to the ALICE electronic logbook, provides experts with an easy way to look at the monitoring histograms from outside the Control Room. AMORE is capable to access a small part of the raw data and perform some online analysis, that in the past required much longer, giving a crucial feedback on the quality of the data. During Run1 DQM was successfully used to spot issues and avoid recording bad quality data.
The work performed during LS1 has been devoted to the improvement of several aspects, like the increase in automatic checks, the integration of new systems, such as DCal and AD, the optimization of the online Event Display and the addition of new useful plots to be monitored by shifters. Continuous interactions between the users and the framework developers are one of the most important aspects since the beginning of the AMORE development and currently during Run2, in order to guarantee good performance of the ALICE DQM, that has to handle 19 detectors and DAQ, HLT and Trigger systems.
LHCb
DQM at LHCb during Run 1 was essentially divided in two parts. First of all, in the online phase the correct functioning of the detector was monitored by the pit crew ensuring that all components are always functioning at their best. Every sub-detector provides its own monitoring allowing the shifter to have real time control on fundamental quantities such as voltages, occupancies, hot or dead channels, temperatures and so on. Automatic comparison with information stored in databases provides alarms helping the shifter to identify problems as soon as they appear. They can then make all necessary adjustments immediately with minimal data loss, also thanks the extremely fast run change developed by the LHCb Online Team.
The data accumulated is then transferred onto the Grid storage for reconstruction. Once this is completed, usually a few days after a run has been collected, a second offline DQ step is performed where quantities like reconstruction efficiencies, particle identification efficiencies, photon and electron hypothesis are analysed. As an outcome of this process the DQ shifter assigns each run with an "OK" or "BAD" flag. Once flagged, OK runs are immediately available to the collaboration for physics analysis.
As a consequence of the real-time controls performed at the pit only less than 1% of the data accumulated by LHCb has been flagged as BAD by the offline step, as shown in the following plot for 2012.
The changes in our trigger and DAQ scheme for Run 2 have had great impact on DQM. As a consequence a dedicated computing farm at the pit will process a subset of a few tens of Hz of the events selected by our trigger. This will allow monitoring of the reconstructed data immediately after it is collected, without waiting for the delays introduced by the processing on the Grid, with almost immediate feedback.
DQM at LHCb is the result of close collaboration between experts from all subdetectors, the Trigger, Online and Offline groups. Thanks to their constant and invaluable help the DQM team has been able to provide this crucial service to the collaboration and to guarantee an extremely high quality in the data used for physics. We are now looking forward to Run 2 where the upgrades made to our trigger and DAQ and the new running conditions make maintaining such high standards an exciting challenge.
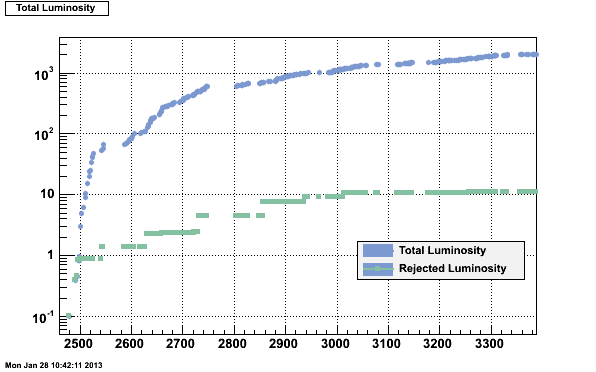
Plot generated by the LHCb DQM system: It can be seen that less than 1% of the data accumulated by LHCb has been flagged as BAD by the offline step which is due to the real-time controls performed at the pit.
The author would like to thank Daniele De Gruttola & Barthelemy Von Haller (ALICE), Sarah Demers, James Frost, Anyes Taffard (ATLAS), Daniel Duggan & Federico De Guio (CMS) and Marco Adinolfi (LHCb) for their valuable input and comments in the preparation of this article.